Echtzeit-Analytics: Computer Vision im Eishockey
Blogbeitrag vom 28. September 2025
von Kevin Lancashire (Link zum Original-Text auf Englisch)

Computer Vision im Eishockey bezeichnet den Einsatz fortschrittlicher Technologien zur Analyse und Interpretation der Spieldynamik anhand visueller Daten. Diese innovative Anwendung hat in den letzten Jahren an Bedeutung gewonnen, da Teams und Analysten ausgefeilte Algorithmen nutzen, um die Spielerverfolgung, Leistungsanalyse und Spielstrategien zu verbessern. Die Integration von Computer Vision hat die traditionellen Methoden der Spielerbewertung und Strategieformulierung revolutioniert und einen bedeutenden Wandel hin zu datengestützten Entscheidungen in diesem Sport bewirkt. Bemerkenswerte Beiträge von Unternehmen wie Sportlogiq haben das Potenzial der Computer Vision unterstrichen, bisher nicht wahrnehmbare Erkenntnisse zu liefern, von denen Teams in der National Hockey League (NHL) und darüber hinaus profitieren.
Die Entwicklung der Computer Vision im Eishockey lässt sich bis in die späten 1990er Jahre zurückverfolgen, als die Einführung von Datenbanken wie RinkNet begann, die Landschaft der Spieleranalyse zu verändern. Angesichts der steigenden Nachfrage nach präziseren und besser verwertbaren Daten haben die Teams Technologien eingeführt, die die Verfolgung von Spielerbewegungen und Spielereignissen automatisieren und so die Erstellung wertvoller Leistungskennzahlen erleichtern. Die besonderen Herausforderungen dieses Sports – wie hohe Spielgeschwindigkeit, Sichtbehinderungen durch Spieler und Bewegungsunschärfe – erforderten jedoch die Entwicklung spezieller Techniken, um eine genaue Analyse zu gewährleisten.
Die Fortschritte in der Computer Vision haben zwar zahlreiche Vorteile gebracht, sind aber nicht unumstritten. Bedenken hinsichtlich des Datenschutzes und der ethischen Implikationen der Leistungsüberwachung sind zu wichtigen Themen innerhalb des Sports geworden. Probleme im Zusammenhang mit algorithmischer Voreingenommenheit, Datenqualität und Widerstand von Spielern und Trainern gegenüber datengestütztem Feedback stellen ebenfalls Herausforderungen für die breite Einführung dieser Technologien dar.
Da sich dieses Gebiet weiterentwickelt, wird erwartet, dass laufende Forschungen und Innovationen die Anwendung der Computer Vision im Eishockey weiter verfeinern und möglicherweise die Art und Weise verändern werden, wie das Spiel gespielt und von den Fans erlebt wird.
Geschichte
Die Anwendung von Computer Vision in der Eishockey-Analytik lässt sich auf Fortschritte in der Datenerfassungs- und Analysetechnologie zurückführen. Ein bedeutender Wendepunkt erfolgte Ende der 1990er Jahre mit der Einführung von RinkNet, einer umfassenden Datenbank, in der Spielerstatistiken und Ranglisten für die NHL katalogisiert wurden. Diese Innovation markierte den Beginn einer neuen Ära, in der traditionelle Scouting-Methoden vor Umbrüchen standen und Scouts dazu veranlassten, sich an digitale Tools zur Bewertung der Spielerleistung anzupassen.
In den folgenden Jahren gewann die Integration fortschrittlicher Analysen im Profisport zunehmend an Bedeutung, insbesondere beeinflusst durch die Pionierarbeit des amerikanischen Statistikers Bill James auf dem Gebiet der Sportstatistik.
Als die Teams das Potenzial der Datenanalyse für fundierte Entscheidungen erkannten, stieg die Nachfrage nach ausgefeilten Analysemethoden, was zur Erforschung der Computer Vision als praktikable Lösung für die Eishockeyanalyse führte. Die Entwicklung der Computer-Vision-Technologie ermöglicht es den Teams, die Bewegungen der Spieler und die Spieldynamik mit beispielloser Genauigkeit zu verfolgen. Frühe Modelle basierten auf manuellen Anmerkungen und einfachen Tracking-Methoden, aber seitdem wurden erhebliche Fortschritte bei der Automatisierung dieser Prozesse erzielt. So stellte beispielsweise die Entwicklung einer speziell für die Eishockeyanalyse konzipierten Computer Vision Pipeline einen wichtigen Meilenstein dar, da sie die effiziente Extraktion und Analyse von Videodaten aus Spielen ermöglichte.
Mit dem Fortschritt der Technologie wuchsen auch die Herausforderungen bei ihrer Umsetzung. Eishockey stellt die Computer Vision vor einzigartige Hindernisse, darunter rasante Spielaktionen, starke Verdeckungen und Bewegungsunschärfen, die die Verfolgung von Spielern und Pucks erschweren.
Trotz dieser Hürden unterstreicht die zunehmende Bedeutung der Computer Vision in der Eishockey-Analyse ihre Bedeutung für die Bewertung von Spielern, strategische Entscheidungen und die Gesamtleistung des Teams.
Heute entwickelt sich die Computer Vision weiter, wobei die Forschung und Entwicklung darauf abzielt, ihre Anwendung im Sport zu verbessern und ihre Rolle in der modernen Eishockey-Analyse weiter zu festigen.
Anwendung von Computer Vision im Ice Hockey
Computer Vision hat sich zu einer Schlüsseltechnologie entwickelt, die verschiedene Aspekte des Eishockeys verbessert, von der Spielerverfolgung bis zur Leistungsanalyse. Die besonderen Herausforderungen, die sich aus dem hohen Tempo, den starken Sichtbehinderungen und Bewegungsunschärfen dieses Sports ergeben, haben zur Entwicklung spezieller Computer-Vision-Techniken geführt, die diese Probleme effektiv lösen.
Spielerverfolgung und -identifikation
Eine der Hauptanwendungen von Computer Vision im Eishockey ist die Verfolgung und Identifizierung von Spielern während der Spiele. Diese Aufgabe ist aufgrund der schnellen Bewegungen der Spieler, der erheblichen Sichtbehinderungen zwischen Spielern und Hindernissen sowie der Ähnlichkeit der Mannschaftstrikots, bei denen oft nur die Trikotnummern als Unterscheidungsmerkmal dienen, sehr komplex.
Neueste Entwicklungen nutzen Algorithmen wie StrongSORT, die Deep Learning mit traditionellen Verfolgungsmethoden kombinieren, um eine konsistente Identifizierung der Spieler während des gesamten Spiels zu gewährleisten.
Automatisierte Systeme zur Verfolgung von Spielern in NHL-Übertragungen bestehen in der Regel aus drei Schlüsselkomponenten: Spielerverfolgung, Mannschaftsidentifizierung und Identifizierung einzelner Spieler.
Diese Systeme können Daten generieren, die verschiedene nachgelagerte Aufgaben wie die Erkennung von Spielereignissen, die Analyse von Leistungskennzahlen und die Bewertung von Strategien unterstützen.
Schläger-Erkennung und Bewegungsanalyse
Eine weitere wichtige Anwendung ist die zuverlässige Erkennung von Hockeyschlägern inmitten visueller Störsignale. Angesichts des hohen Tempos des Spiels wurde die SLDA-Technik (Synthetic Local Data Augmentation) entwickelt, um die Segmentierungsgenauigkeit durch Einfügen realer Stockmasken in die Übertragungsbilder zu verbessern. Diese Methode berücksichtigt verschiedene Transformationen wie Bewegungsunschärfe und Beleuchtungsanpassungen und verbessert letztendlich die Erkennung von Schlägern, insbesondere wenn diese verdeckt sind oder sich schnell bewegen.
Leistungsanalyse
Computer Vision spielt auch eine wichtige Rolle bei der Leistungsanalyse, indem es Einblicke in die Bewegungen der Spieler und die Spielsdynamik liefert. Durch die Verfolgung der Spieler können Systeme wichtige Leistungskennzahlen wie Durchschnittsgeschwindigkeit, zurückgelegte Gesamtstrecke und Offensivdruck berechnen und so eine detaillierte Analyse der individuellen und der Teamleistung während eines Spiels ermöglichen.
Diese Kennzahlen können mithilfe von Overlays auf dem Broadcast-Feed in Echtzeit visualisiert werden, was das Zuschauererlebnis für Fans und Trainer gleichermaßen verbessert.
Verbesserte Spiel Strategien
Die aus Computer-Vision-Anwendungen generierten Daten können wichtige Erkenntnisse für Trainingsstrategien und Spielplanung liefern. Durch die Analyse der Tracking-Daten können Trainer die Positionierung der Spieler beurteilen, offensive und defensive Spielzüge bewerten und Trainingsprogramme optimieren, um Schwächen zu beheben, die während der Spiele festgestellt wurden.
Die Möglichkeit, die Bewegungen der Spieler und die Interaktionen innerhalb des Teams umfassend zu visualisieren, ermöglicht es den Teams, datengestützte Entscheidungen zu treffen, die den Spielausgang beeinflussen können.
Künftige Entwicklungen
Mit dem Fortschritt der Technologie wird die Integration von Computer Vision im Eishockey voraussichtlich weiter zunehmen. Innovationen wie die KI-gestützte Bewertung von Verletzungsrisiken und eine stärkere Einbindung des Publikums durch immersive Erlebnisse stehen bevor und versprechen, die Art und Weise, wie dieser Sport gespielt und verfolgt wird, zu revolutionieren.
Die laufenden Forschungen in diesem Bereich deuten auf eine vielversprechende Zukunft für die Anwendungen von Computer Vision in der Eishockey-Analytik und darüber hinaus hin.
Verwendete Technologien
Computer Vision Anwendungen im Eishockey
Computer-Vision-Technologien gewinnen im Eishockey zunehmend an Bedeutung, insbesondere für die Verbesserung des Trainings, die Leistungsanalyse und das Echtzeit-Feedback während der Spiele. Ein solches System ist HELIOS™ LIVE, das ein mobiles Gerät mit dem Helios Core-Leistungssensor eines Athleten verbindet und es Trainern ermöglicht, Echtzeit-Messdaten und biomechanisches Feedback zu erhalten.
Diese Technologie nutzt fortschrittliche Computer-Vision-Algorithmen, die Athleten automatisch verfolgen und wichtige Eigenschaften wie Schrittweite und Gelenkwinkel messen, wodurch sofortiges korrigierendes Feedback möglich ist.
Kamera Systeme
Kamerasysteme spielen eine entscheidende Rolle bei der Aufnahme von hochauflösenden Videos für Analysezwecke. Diese Systeme können verschiedene Konfigurationen nutzen, darunter Hochgeschwindigkeitskameras, die schnelle Bewegungen präzise erfassen, und 360-Grad-Kameras, die einen umfassenden Blick auf das Spielfeld bieten.
Solche Aufnahmen aus mehreren Blickwinkeln sind für die Analyse von Spielerbewegungen, Spieldynamiken und kritischen Momenten wie Toren oder Strafen unerlässlich. Die Integration dieser Kamerasysteme mit Computervisionsalgorithmen ermöglicht umfassende Leistungsbewertungen und taktische Auswertungen.
Echtzeit Feedback Mechanismen
Echtzeit-Feedback ist ein wesentlicher Vorteil der Bildverarbeitung im Eishockeytraining. Durch den Einsatz von Systemen wie HELIOS™ können Techniktrainer Trainingseinheiten aufzeichnen und Videos anhalten, um mit den Athleten die Biomechanik zu besprechen und so ihr Verständnis für die Techniken zu verbessern, ohne den Trainingsfluss zu unterbrechen.
Diese unmittelbare Feedbackschleife trägt zur Förderung einer positiven Feedbackkultur bei, die für die Entwicklung der Athleten und die Verbesserung ihrer Leistung von entscheidender Bedeutung ist.
Datenschutz und Sicherheit
Wie bei jeder Technologie, die Leistungsdaten erfasst, gibt es Überlegungen hinsichtlich Datenschutz und -sicherheit. Für Organisationen, die diese Systeme nutzen, ist es von entscheidender Bedeutung, die Einhaltung der Datenschutzbestimmungen sicherzustellen und das Vertrauen zwischen Sportlern und Trainern zu fördern.
Durch die Priorisierung des Datenschutzes können Unternehmen die mit der Implementierung fortschrittlicher technologischer Lösungen verbundenen Herausforderungen bewältigen und gleichzeitig die Vertraulichkeit und Sicherheit der Sportler gewährleisten.
Zukünftige Innovationen
Mit Blick auf die Zukunft verspricht die Integration von Augmented Reality (AR) und maschinellem Lernen in Trainingsmethoden eine Revolutionierung der Art und Weise, wie Sportler trainieren und mit Technologie interagieren. Durch die Kombination dieser Technologien mit traditionellen Trainingsmethoden können Teams das Engagement der Sportler steigern und die Trainingseffizienz optimieren und damit neue Maßstäbe in Sachen Leistung setzen.
Die kontinuierliche Weiterentwicklung personalisierter KI-Trainingssysteme deutet zudem auf einen Trend hin zu maßgeschneiderten Trainingserlebnissen hin, die auf die individuellen Bedürfnisse der Sportler zugeschnitten sind.
Fallstudien
Eye-Tracking Technologie im Sport
Dank der jüngsten Fortschritte in der Eye-Tracking-Technologie können Forscher nun umfassende Analysen der visuellen Aufmerksamkeit von Spielern während sportlicher Aktivitäten durchführen. In einer Studie mit Eishockeyspielern wurde das Eye-Tracking für jedes Auge einzeln durchgeführt, was zu der Empfehlung führte, dass zukünftige Forschungen die Daten pro Auge mitteln sollten, um die Auswirkungen von Tracking-Fehlern zu minimieren.
Dieser Ansatz zielt darauf ab, die Zuverlässigkeit der Ergebnisse in Studien zur sportlichen Leistung zu verbessern. Die Forschung wurde unter ethischen Gesichtspunkten durchgeführt, wobei alle Teilnehmer ihre Zustimmung gaben und die Studie von der Ethikkommission der Russischen Psychologischen Gesellschaft genehmigt wurde.
KI-gestützte Analyse bei Canlan Ice Sports
Ein Prototyp-System, das künstliche Intelligenz nutzt, ist derzeit in der Canlan Ice Sports-Anlage auf dem Keele Campus der York University im Einsatz, wo es während der Heimspiele der York Lions Daten erfasst.
Dieses System zeichnet Spielaufnahmen auf und analysiert sie, um Erkenntnisse zu gewinnen, die dem menschlichen Auge sonst entgehen würden. Das Projekt, das vom VISTA Prototyping Fund finanziert wurde, soll das Engagement der Gemeinschaft fördern, indem es Sportveranstaltungen zugänglicher macht und gleichzeitig die mit dem Besuch verbundenen Verkehrsstaus reduziert.
Der Einfluss von Sportlogiq auf die NHL
Sportlogiq hat sich zu einem Wegbereiter im Bereich der Sportanalyse entwickelt, insbesondere im Eishockey. Das 2015 gegründete Unternehmen nutzt Computer Vision und maschinelles Lernen, um NHL-Teams Erkenntnisse aus Daten zu liefern, die für menschliche Beobachter oft nicht wahrnehmbar sind.
Sportlogiq betreut 31 NHL-Teams und verfolgt detailliert die Bewegungen und Interaktionen der Spieler, sodass die Teams ihre Strategien und Spielerentwicklungsprozesse verfeinern können. Der Fokus auf datengestützte Entscheidungsfindung spiegelt einen Wandel in der Branche hin zu innovativen Lösungen wider, die die Leistung und das Training verbessern.
Verbesserung der Spielerentwicklung durch Analytik
Neben der Erfassung von Spielerstatistiken nutzen NHL-Teams zunehmend fortschrittliche Analysemethoden, um das Potenzial und die Entwicklung von Spielern zu bewerten. Die Integration von Technologie in die Spielerentwicklung umfasst nun nicht mehr nur die Überwachung von Toren und Vorlagen, sondern auch differenziertere Kennzahlen wie Puckkämpfe und Puckgewinne.
Diese Entwicklung hat zu einem ausgefeilteren Ansatz bei der Talentsuche und Spielerbewertung geführt, bei dem umfassende Datenanalysen zur Entscheidungsfindung und Strategieentwicklung herangezogen werden.
Anhand dieser Fallstudien verdeutlicht der Einsatz von Computer Vision und künstlicher Intelligenz im Eishockey einen wachsenden Trend zu datengestützten Methoden, die sowohl die Leistung der Spieler als auch das Engagement der Fans für diesen Sport verbessern.
Herausforderungen und Grenzen
Trotz der vielversprechenden Fortschritte in der Computer-Vision-Technologie für Eishockey bestehen weiterhin einige Herausforderungen und Einschränkungen, die die volle Ausschöpfung ihres Potenzials behindern.
Probleme mit der Datenqualität
Eine der größten Herausforderungen ist die Qualität der während der Spiele gesammelten Daten. Inkonsistente oder unvollständige Aufzeichnungen können zu fehlerhaften Analysen führen und die Aussagekraft der aus den Daten gewonnenen Erkenntnisse beeinträchtigen.
Dieses Problem erfordert strenge Qualitätskontrollen und strukturierte Ansätze, um sicherzustellen, dass die Daten praktischen Zwecken dienen, ohne dass dabei ihre Integrität beeinträchtigt wird.
Datenschutz und Ethische Fragen
Der Datenschutz ist ein weiterer wichtiger Aspekt. Die Erfassung und Analyse von Leistungsdaten kann erhebliche Bedenken hinsichtlich der Privatsphäre einzelner Athleten und der Datensicherheit aufwerfen.
Die Einhaltung von Vorschriften wie der Datenschutz-Grundverordnung (DSGVO) in Europa unterstreicht die Notwendigkeit für Organisationen, verantwortungsbewusst und transparent mit Daten umzugehen und sicherzustellen, dass die Rechte der Athleten gewahrt werden.
Die Umsetzung ethischer Rahmenbedingungen ist von entscheidender Bedeutung, um Organisationen bei der verantwortungsvollen Nutzung von Daten anzuleiten und einen Ausgleich zwischen kommerziellen Interessen und dem Schutz personenbezogener Daten zu schaffen.
Finanzielle Schranken
Die mit der Einführung von Computer-Vision-Systemen verbundenen finanziellen Kosten können prohibitiv sein. Die anfänglichen Investitionen in Hardware und Software sowie die laufenden Kosten für Wartung und Schulungen können für viele Teams und Organisationen eine Eintrittsbarriere darstellen.
Zwar gibt es innovative Lösungen zur Budgetoptimierung, doch der Bedarf an erheblichen finanziellen Ressourcen bleibt eine erhebliche Einschränkung.
Menschliches Eingreifen
Technologie kann Schiedsrichtern zwar helfen und die Entscheidungsfindung auf dem Eis verbessern, sie kann jedoch menschliches Eingreifen nicht vollständig ersetzen. Aufgrund der Subjektivität einiger Entscheidungen im Sport wird menschliches Urteilsvermögen auch weiterhin eine entscheidende Rolle bei der Schiedsrichterleistung spielen, selbst wenn Computer-Vision-Tools Unterstützung bieten.
Widerstand gegen Feedback
Algorithmische Verzerrung und Zuverlässigkeit
Die in Computer-Vision-Systemen verwendeten Algorithmen müssen robust und gut getestet sein, um zuverlässige Ergebnisse zu gewährleisten. Probleme wie algorithmische Verzerrungen können auftreten, wenn die Datenerfassung nicht umfassend ist, was zu unfairen Bewertungen der Spielerleistung führen kann.
Regelmäßige Überprüfungen und Aktualisierungen sind notwendig, um Genauigkeit und Zuverlässigkeit zu gewährleisten, insbesondere in dynamischen Umgebungen wie dem Eishockey, wo sich die Spielbedingungen und die Dynamik der Spieler schnell ändern können.
Künftige Trends
Fortschritte in der Bildverarbeitung für Eishockey
Die Integration von Computer-Vision-Technologie im Eishockey steht vor einem bedeutenden Wachstum, da sie sich parallel zu den Fortschritten in den Bereichen künstliche Intelligenz (KI) und Datenanalyse weiterentwickelt. Dieser Trend verbessert nicht nur die Art und Weise, wie Teams ihre Leistung analysieren, sondern auch, wie Fans sich mit dem Sport beschäftigen. Mit einem prognostizierten Marktwachstum von 2,39 Milliarden US-Dollar auf 3,1 Milliarden US-Dollar bis Ende 2025 und einem erwarteten Anstieg auf 8,7 Milliarden US-Dollar bis 2029 wächst die Nachfrage nach Computer-Vision-Lösungen im Sport, insbesondere im Eishockey, rasant.
Verbesserte Analyse der Spielerleistung
Eine der wichtigsten Anwendungen der Bildverarbeitung im Eishockey ist die Möglichkeit, die Bewegungen der Spieler zu verfolgen und das Spielgeschehen in Echtzeit zu analysieren. Mithilfe moderner Kamerasysteme können Teams detaillierte Daten über die Geschwindigkeit, Positionierung und Entscheidungsfindung der Spieler während der Spiele sammeln. Diese Informationen sind für Trainer und Analysten von unschätzbarem Wert, da sie ihnen ermöglichen, gezielte Trainingsprogramme und Spielstrategien zu entwickeln, die die Gesamtleistung des Teams verbessern. Die Möglichkeit, präzises Feedback zu geben, fördert ein Umfeld der kontinuierlichen Verbesserung und datengestützten Entscheidungsfindung, was letztlich zu einer höheren Kapitalrendite (ROI) für die Teams beiträgt.
Immersive Fan-Erlebnisse
Neben der Leistungsanalyse verändert die Computer-Vision-Technologie auch das Fan-Engagement. Durch den Einsatz von Augmented Reality (AR) können Fans Spiele aus einzigartigen Perspektiven erleben, beispielsweise aus der Sicht der Athleten oder durch den Zugriff auf Echtzeitstatistiken und Spieler-Tracking-Daten während der Spiele. Dieses immersive Erlebnis verbessert die Interaktion der Fans mit dem Sport, schafft tiefere Verbindungen und erhöht die Loyalität.
Durch den Einsatz dieser Technologien steigern die Teams nicht nur das Engagement ihres Publikums, sondern erschließen auch neue Einnahmequellen durch verbesserte Werbe- und SponsoringmodelleDie Zukunft der AI im Eishockey
Mit Blick auf die Zukunft wird die Entwicklung von KI und Computer Vision im Eishockey wahrscheinlich die Entwicklung von Predictive-Analytics-Tools umfassen, mit denen Spielausgänge und Spielerleistungen vorhergesagt werden können. Diese Fortschritte werden es den Teams ermöglichen, fundiertere Entscheidungen in Bezug auf Spielertransfers, Verletzungsmanagement und Spieltaktiken zu treffen. Da sich ethische Überlegungen und Bedenken hinsichtlich der Datensicherheit weiterentwickeln, müssen Organisationen diese Herausforderungen sorgfältig angehen, um das volle Potenzial der Computer-Vision-Technologien auszuschöpfen, ohne die Integrität des Sports zu beeinträchtigen.
Die Zukunft ist sichtbar: Wie Computer Vision unsere Welt verändert
Blogbeitrag vom 20. September 2025
von Kevin Lancashire (Link zum Original-Text auf Englisch)

BEHAVIOR-1K ist ein wichtiger Benchmark-Datensatz, der zur Weiterentwicklung der Erkennung menschlichen Verhaltens (HBR) im Bereich der Bildverarbeitung verwendet wird. Er bietet eine umfassende Plattform für das Training und die Bewertung von Modellen des maschinellen Lernens für eine Vielzahl menschlicher Handlungen und verbessert so die Genauigkeit der Gestenerkennung und die Gesamtleistung von HBR-Systemen. Dieser Datensatz ist für die Entwicklung von Anwendungen in den Bereichen Sicherheit, Gesundheitswesen und soziale Robotik von entscheidender Bedeutung.
Schlüsselkonzepte und Fortschritt
Der Bereich HBR hat dank Innovationen im Bereich der neuronalen Netzwerkarchitekturen erhebliche Fortschritte erzielt. Frühe Modelle wie Neocognitron und LeNet-5 legten den Grundstein für die Bildverarbeitung, während AlexNet die Leistungsfähigkeit von Deep Learning und großen Datensätzen unter Beweis stellte. In jüngerer Zeit haben hybride Modelle, die die Stärken von Convolutional Neural Networks (CNNs) und Vision Transformers (ViTs) kombinieren, zu erheblichen Verbesserungen bei der Analyse und Interpretation visueller Daten geführt. Diese Fortschritte ermöglichen eine effektivere Verfolgung menschlicher Aktivitäten und die Erkennung von Anomalien, was für Anwendungen wie Videoüberwachung und autonome Fahrzeuge von entscheidender Bedeutung ist.
Eine weitere wichtige Innovation ist der Einsatz von Aufmerksamkeitsmechanismen, die es Modellen ermöglichen, sich ähnlich wie Menschen auf wichtige Teile eines Bildes oder Videos zu konzentrieren und so das Kontextbewusstsein und die Informationsverarbeitung zu verbessern.
Herausforderungen und zukünftige Ausrichtung
Trotz dieser Fortschritte bleiben Herausforderungen bestehen. Die Variabilität menschlicher Handlungen und die Komplexität realer Umgebungen können den Einsatz von HBR-Systemen erschweren. Hochwertige annotierte Datensätze sind für das Training von Algorithmen unerlässlich, ihre Erstellung ist jedoch oft arbeitsintensiv und kostspielig. Darüber hinaus sind ethische Überlegungen hinsichtlich Datenschutz und algorithmischer Verzerrung wichtige Themen, die im Zuge der technologischen Weiterentwicklung angegangen werden müssen.
Mit Blick auf die Zukunft wird sich die Entwicklung von HBR auf die Entwicklung hybrider Modelle konzentrieren, die robuster und skalierbarer für reale Anwendungen sind. Die kontinuierliche Weiterentwicklung von Benchmarks wie BEHAVIOR-1K wird dabei eine wesentliche Rolle spielen und die Bedeutung der Zusammenarbeit zwischen Wissenschaft und Industrie unterstreichen, um Herausforderungen zu bewältigen und Chancen zu nutzen.
Quelle:
https://behavior.stanford.edu/
Keine Flecken mehr: Die gnadenlose Präzision der Computervision für Bananen
Blogbeitrag vom 13. September 2025
von Kevin Lancashire (Link zum Original-Text auf Englisch)

Computer Vision (CV), die Technologie, die Maschinen das „Sehen“ beibringt, revolutioniert die globale Lieferkette für landwirtschaftliche Produkte. Für besonders empfindliche Produkte wie Bananen, die schnell verderben können, bietet sie eine Lösung zur deutlichen Steigerung von Effizienz, Qualität und Transparenz.
Effizienz und Qualität im Fokus
Der manuelle Qualitätskontrollprozess ist oft subjektiv und ineffizient, was zu Unstimmigkeiten und Verlusten führt. Computer-Vision-Systeme lösen dieses Problem, indem sie Bananen in Echtzeit scannen und bewerten. Sie analysieren nicht nur die Farbe, sondern auch Größe, Form, Textur und das Vorhandensein von Mängeln wie Druckstellen oder Krankheiten.
-
Präzision: Eine Studie hat gezeigt, dass automatisierte Sortiersysteme eine Genauigkeit von über 90 % bei der Klassifizierung von Bananen nach ihrem Reifegrad erreichen können.
-
Geschwindigkeit: Diese Systeme verarbeiten Tonnen von Früchten pro Stunde und steigern so den Durchsatz erheblich.
-
Abfallreduzierung: Durch das frühzeitige Aussortieren fehlerhafter Früchte minimieren sie Produktverluste und steigern die Rentabilität.
Der Einsatz von CV schafft objektive, standardisierte Daten und legt damit den Grundstein für eine lückenlose Rückverfolgbarkeit entlang der gesamten Lieferkette.
Von der Farm zum Konsumenten: Transparenz schaffen
Die von CV-Systemen generierten Daten bilden die Grundlage für eine neue Ära der Transparenz in der Lieferkette. Sie ermöglichen es, den Zustand jeder Charge oder sogar jeder einzelnen Frucht an einem bestimmten Punkt in der Lieferkette zu dokumentieren.
Ein zukünftiger Treiber für diese Entwicklung ist der digitale Produktpass (DPP). Obwohl er zunächst für andere Branchen gilt, wird er wahrscheinlich in Zukunft auch für den Lebensmittelsektor verbindlich werden. Der DPP speichert relevante Produktinformationen digital. Computer-Vision-Systeme können als Datenlieferanten fungieren, indem sie die visuelle Qualität eines Produkts in Echtzeit erfassen und diese Daten automatisch in den DPP übertragen.
Stellen Sie sich vor: Eine Banane wird von einem CV-System geprüft. Ihr Reifegrad, ihre Abmessungen und etwaige Mängel werden in den digitalen Pass der Banane eingetragen. Durch das Scannen eines QR-Codes kann der Einzelhändler oder sogar der Endverbraucher auf diese Daten zugreifen. Dies schafft Vertrauen und Glaubwürdigkeit und kann bei der Verwaltung von Produktrückrufen von unschätzbarem Wert sein.
Was die Zukunft bringen wird
Die Technologie entwickelt sich ständig weiter. In Zukunft wird die prädiktive Analytik die nächste Stufe der Optimierung sein. Systeme werden Daten aus CV- und anderen Sensoren nutzen, um vorherzusagen, wann eine Banane ihre optimale Reife erreicht hat. So können Logistik und Lagerung perfekt geplant werden, um Verderb zu vermeiden.
Langfristig werden Robotik und Smart Farming die Bananenernte revolutionieren. Mit Computer-Vision-Technologie ausgestattete Roboter könnten den perfekten Zeitpunkt für die Ernte erkennen und die Früchte präzise pflücken. Dies erhöht den Ertrag, reduziert den Arbeitsaufwand und verbessert die Qualität, da die Früchte im optimalen Zustand geerntet werden.
Fazit: Computer Vision ist nicht nur ein Trend, sondern ein transformativer Wandel für die Agrarlogistik. Sie liefert die objektiven Daten, die für eine effiziente, nachhaltige und transparente Lieferkette von heute und morgen unerlässlich sind. Der Nutzen für Unternehmen liegt auf der Hand: höhere Effizienz, weniger Abfall und gestärktes Vertrauen bei Einzelhändlern und Verbrauchern. Die Integration dieser visuellen Intelligenz in bestehende Systeme ist der nächste entscheidende Schritt.
Wie sehen Sie die Integration visueller Daten in die Rückverfolgbarkeit Ihrer Produkte?
Quellen:
Wirtschaftlicher Nutzen und Leistungsmetriken
Diese Studie vergleicht manuelles und automatisiertes Sortieren und liefert konkrete Daten zu Effizienz, Durchsatz und der prognostizierten Rentabilitätssteigerung von bis zu 19 % durch den Einsatz automatisierter Sortieranlagen.
Computer Vision als Bahnbrechende Neuerung
Dieser Bericht befasst sich mit der Rolle der Bildverarbeitung bei der Automatisierung der Sortierung von Obst und Gemüse. Er verweist auf die hohe Klassifizierungsgenauigkeit von über 95 % unter Verwendung fortschrittlicher Deep-Learning-Modelle und erläutert die Vorteile der Technologie für die Qualitätssicherung und Abfallreduzierung.
Nachverfolgbarkeit und Digitale Produktpässe (DPP)
Dieser Artikel erläutert den Digital Product Passport (DPP) als System zum Sammeln und Teilen von Produktdaten. Er hebt die Rolle des DPP bei der Verbesserung der Rückverfolgbarkeit und der Einhaltung gesetzlicher Anforderungen hervor, wie beispielsweise der EU-Ökodesign-Verordnung für nachhaltige Produkte.
Blogbeitrag vom 5. September 2025
Die Revolution der Computervision: Was bedeutet das für Ihr Unternehmen?
von Kevin Lancashire (Link zum Original-Text auf Englisch)

Erinnern Sie sich noch daran, als Ihr Smartphone Ihr Gesicht nicht erkennen konnte oder Lagerroboter einen Schraubenschlüssel nicht von einem Steckschlüssel unterscheiden konnten? Wir haben einen langen Weg zurückgelegt. Der Sprung in der Computer Vision – der Technologie, die Maschinen das „Sehen” beibringt – wurde durch ein einziges, groß angelegtes Projekt namens ImageNet ausgelöst. Dabei handelte es sich nicht nur um einen Datensatz, sondern um einen Katalysator, der die KI grundlegend verändert hat.
Der eigentliche Vorteil? ImageNet machte hochentwickelte visuelle KI zugänglich und leistungsfähig und verschaffte Unternehmen wie dem Ihren einen Wettbewerbsvorteil
Von der Handarbeit zu automatisierter Erkentniss
Jahrzehntelang war es ein langsamer und mühsamer Prozess, einem Computer das Sehen beizubringen. Entwickler mussten jedes Detail – Kanten, Ecken und Formen – für jedes Objekt manuell programmieren. Das war langsam, teuer und auf wenige spezifische Aufgaben beschränkt. Stellen Sie sich das wie eine handgezeichnete Karte eines einzelnen Stadtviertels vor: Sie ist nützlich, aber nicht skalierbar.
Der von ImageNet geleistete Durchbruch hat das Paradigma verändert. Anstatt für jedes Problem manuell Lösungen zu entwickeln, können wir nun eine riesige Datenmenge in ein Modell einspeisen und es selbstständig lernen lassen. Dieser Wandel von der manuellen Entwicklung von Funktionen zum automatischen Lernen aus Daten ist die Grundlage für die wertvollsten visuellen KI-Anwendungen von heute.
Ihr Vorteil: Dank dieses neuen Ansatzes benötigen Sie keine riesigen, maßgeschneiderten Datensätze mehr, um Ihre visuellen Herausforderungen zu lösen. Die Schwerstarbeit wurde bereits geleistet.
Mit ‹vortrainierten› Modellen neue Geschäftsfelder erschliessen
Der größte Vorteil der ImageNet-Revolution ist das Konzept des Transferlernens. Es ist, als hätte man einen Meisterlehrling, der die Grundlagen bereits jahrelang studiert hat. Diese KI-Modelle haben schon eine universelle Sprache visueller Muster gelernt – von Texturen und Formen bis hin zu ganzen Objekten.
Anstatt bei Null anzufangen, nehmen wir nun eines dieser leistungsstarken, „vortrainierten” Modelle und optimieren es mit einer kleinen Menge Ihrer spezifischen Daten.
Was bedeutet das für Sie?
-
Schnellere Entwicklung: Verkürzen Sie die Zeit für die Bereitstellung einer visuellen KI-Lösung von Monaten auf Wochen.
-
Geringere Kosten: Reduzieren Sie die Menge der zu erfassenden und zu kennzeichnenden Daten erheblich und sparen Sie so Zeit und Geld.
-
Breitere Anwendungsgebiete: Benutzen Sie diese Technologie für eine riesige Menge von Aufgaben von der automatisierten Qualitätskontrolle in einer Produktionslinie bis zum Erkennen von Pflanzenkrankheiten in Agrikulturen.
Das Resultat ist eine demokratisierte visuelle KI, die Sie befähigt Probleme zu lösen, die einst zu komplex oder zu teuer waren, um sie anzugehen.
Der Blick voraus: Die nächste KI-Generation
Der Bereich der KI entwickelt sich ständig weiter, und wir lernen aus den anfänglichen Herausforderungen der ImageNet-Ära. Der Schwerpunkt verlagert sich auf die Entwicklung von Modellen, die robuster und unvoreingenommen sind und die reale sie verändernde Welt verstehen können. Neue Methoden, wie beispielsweise solche, die Bildverarbeitung mit Sprache kombinieren, schaffen eine KI, die nicht nur „sieht“, sondern auch den Kontext dessen, was sie sieht, „versteht“.
Die Schlussfolgerung für Sie ist einfach: Die Grundlage ist solide, aber das Potenzial wächst weiter. Wir bewegen uns in Richtung einer KI, die nicht nur ein Werkzeug, sondern ein Partner ist und reichhaltigere Erkenntnisse und zuverlässigere Leistungen bietet. Die Zukunft der visuellen KI wird genauer, fairer und nahtloser sein als je zuvor.
Quellen:
Sources:
ImageNet: Revolution in Image Classification
What is a Pre-trained Model?“ from All About AI
Feature Learning vs. Feature Engineering“ from ZEISS
Blogbeitrag vom 30. August 2025
Wie Technologie im Kampf gegen Malaria und Dengue-Fieber hilft
von Kevin Lancashire (Link zum Original-Text auf Englisch)
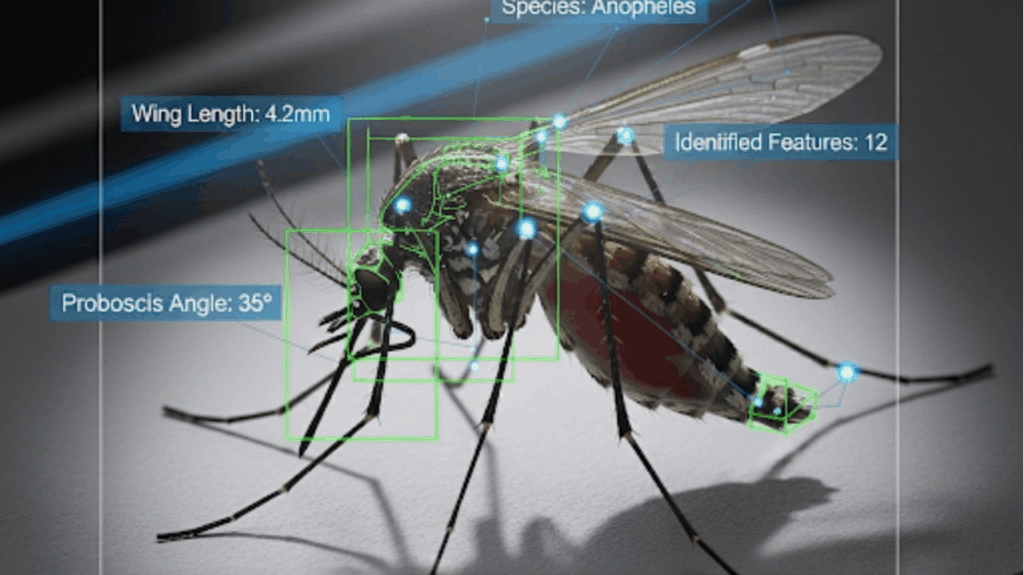
Wir alle haben schon von dem unermüdlichen weltweiten Kampf gegen Krankheiten wie Malaria und Dengue gehört. Aber haben Sie jemals über die stillen Helden an vorderster Front nachgedacht? Nein, nicht nur Wissenschaftler und Ärzte, sondern auch die Technologie, die sie heute einsetzen. Insbesondere Computer Vision (CV) verändert die Situation auf eine Weise, die Sie vielleicht nicht erwarten würden.
Eine intelligentere Art der Diagnose
Stellen Sie sich eine Welt vor, in der die Diagnose von Malaria so einfach ist wie das Aufnehmen eines Fotos. Seit Jahrzehnten ist es Standard, Blutproben unter dem Mikroskop zu untersuchen. Das ist zwar effektiv, erfordert jedoch hochqualifizierte Experten, und in ländlichen, ressourcenarmen Gebieten kann es eine große Herausforderung sein, eine zeitnahe Diagnose zu erhalten.
Hier kommt Computer-Vision (CV) ins Spiel. Forscher verwenden nun künstliche Intelligenz (KI), insbesondere eine Technologie namens Convolutional Neural Networks (CNNs), um digitale Bilder von Blutproben zu analysieren. Diese KI-Modelle können Malariaparasiten schneller und genauer identifizieren und zählen als das menschliche Auge und helfen Ärzten so, eine schnelle und zuverlässige Diagnose zu stellen. Dies ist nicht nur ein Laborexperiment, sondern ein Werkzeug, das eines Tages in den Händen von Gesundheitspersonal vor Ort sein könnte und buchstäblich ein Hightech-Labor in eine abgelegene Klinik bringt.
Den Feind aufspüren
Um eine Krankheit zu bekämpfen, muss man ihren Überträger verstehen – in diesem Fall die Mücke. Zu wissen, wo sich verschiedene Arten befinden, wie sich ihre Populationen verändern und wie sie sich verhalten, ist für eine wirksame Prävention von entscheidender Bedeutung. Aber Millionen winziger, fliegender Insekten aufzuspüren, ist eine gewaltige Aufgabe.
Deshalb wird CV für die Überwachung von Mücken eingesetzt. Mit KI ausgestattete Kameras können verschiedene Mückenarten automatisch identifizieren und klassifizieren, beispielsweise die gefährliche Anopheles-Mücke, die Malaria überträgt. So entsteht eine Echtzeit-„Karte“ der Gefahrenherde, anhand derer Gesundheitsbehörden Ressourcen wie Netze und Sprays genau dort einsetzen können, wo sie am dringendsten benötigt werden. Man kann sich das als intelligentes Überwachungssystem für die öffentliche Gesundheit vorstellen, das uns eine leistungsstarke neue Möglichkeit bietet, dem Ausbruch immer einen Schritt voraus zu sein.
Wie geht es weiter?
Obwohl diese Technologie unglaublich vielversprechend ist, gibt es noch einige Herausforderungen zu bewältigen, von der Integration dieser Tools in bestehende Gesundheitssysteme bis hin zur Gewährleistung ihrer Erschwinglichkeit und Zugänglichkeit. Aber die Richtung ist klar: Durch die Kombination unseres Verständnisses der öffentlichen Gesundheit mit der Kraft der Technologie bauen wir eine effektivere und effizientere Abwehr gegen diese verheerenden Krankheiten auf.
Wie wird die Technologie Ihrer Meinung nach unseren Kampf gegen globale Gesundheitsprobleme weiterhin prägen? Teilen Sie uns Ihre Meinung in den Kommentaren im Originalartikel auf Linkedin mit!
Quellen
Novel Physical and Computer-Based methods for Adult Mosquito Pest Control and Monitoring
Blogbeitrag vom 23. August 2025
Vom Entwurf zur Realität: Die Leistungsfähigkeit KI-gestützter Bauprozess
von Kevin Lancashire (Link zum Original-Text auf Englisch)

Ein lebendiger digitaler Zwilling geht über einen Plan hinaus und gibt Ihnen eine ganzheitliche Ansicht des Lebenszyklus ihres Projekts.
Geschätzte Innovatoren,
die Baubranche erlebt derzeit einen tiefgreifenden digitalen Wandel. Die Zeiten fragmentierter, manueller Prozesse werden durch einen ganzheitlichen, datengestützten Ansatz abgelöst, der Effizienz und Sicherheit neu definiert. Im Zentrum dieses Wandels stehen drei konvergierende Technologien: Computer Vision, Künstliche Intelligenz (KI) und digitale Zwillinge.
Dies ist kein futuristisches Konzept, sondern eine Realität, die bereits jetzt erhebliche, quantifizierbare Vorteile bietet. Durch den Einsatz von KI zur Interpretation von Echtzeitdaten aus Baustellenkameras sind wir in der Lage:
-
Effizienz und Produktivität verbessern: Automatisieren Sie die Fortschrittsverfolgung, indem Sie Echtzeitbilder mit Entwürfen vergleichen. Dies ermöglicht eine kontinuierliche, objektive Berichterstattung und stellt sicher, dass alle Beteiligten über eine einzige Informationsquelle verfügen.
-
Sicherheit und Qualitätskontrolle verbessern: Identifizieren Sie proaktiv potenzielle Gefahren und Verstöße gegen Sicherheitsvorschriften in Echtzeit. Dadurch wird das Sicherheitsmanagement von einem reaktiven zu einem vorausschauenden Ansatz, der Vorfälle verhindert, bevor sie auftreten, und den Ertrag Ihres Projekts schützt.
-
Schaffung eines Wettbewerbsvorteils: Umwandlung großer Mengen visueller Daten in verwertbare Informationen. Dies hilft Ihnen, schnellere und fundiertere Entscheidungen zu treffen, von der Optimierung des Geräteeinsatzes bis zur Rationalisierung der Logistik.
-
Der ultimative Wert dieser Technologien liegt in ihrer Fähigkeit, einen Digitalen Zwilling (Digital Twin) zu speisen – eine lebendige, virtuelle Nachbildung einer physischen Anlage. Dieses leistungsstarke Framework vereint alle Datenquellen auf einer einzigen Plattform und ermöglicht so ein neues Maß an Kontrolle und Einblick, das über den Bau hinausgeht und sich auf die gesamte Betriebsdauer eines Stadions erstreckt.
Angesichts unseres Fokus auf proaktive, lösungsorientierte Kommunikation für das Transpareo-Wachstumsprogramm verstehe ich die Notwendigkeit einer nahtlosen Benutzererfahrung, selbst für eine einfache Aufgabe wie Kopieren und Einfügen. Die direkte Integration der Links in den Text sorgt für eine übersichtlichere, professionellere Präsentation auf Plattformen wie LinkedIn.
Hier ist die überarbeitete Liste mit den direkt in den Text eingebetteten URLs. Sie können diesen gesamten Block kopieren und in einen LinkedIn-Beitrag einfügen.
-
AI security cameras: Entdecken Sie die nächste Generation intelligenter CCTV-Technologie mit KI-gestützten Systemen.
-
The rise of AI in construction: Erfahren Sie, wie KI die Effizienz und Innovation in der Bauindustrie vorantreibt.
-
Real-time construction webcams: Sehen Sie, wie moderne Webcams sich von passiven Werkzeugen zu aktiven Datensensoren wandeln.
-
AI for visual collaboration: Entdecken Sie, wie KI die visuelle Zusammenarbeit und das Projektmanagement vor Ort verbessert.
-
Top use cases for computer vision: Tauchen Sie ein in praktische Beispiele dafür, wie Computer Vision im Bausektor eingesetzt wird.
-
Digital twins in construction: Verstehen Sie die entscheidende Rolle digitaler Zwillinge in modernen Gebäude- und Infrastrukturprojekten.
-
SoFi Stadium’s digital twin: Lesen Sie die offizielle Ankündigung darüber, wie das SoFi-Stadion einen digitalen Zwilling für den Bau und den Betrieb eingesetzt hat.
-
Paris 2024 Olympic Games planning: Sehen Sie, wie die digitale Zwillingstechnologie für die sorgfältige Planung der olympischen Austragungsorte eingesetzt wurde.
-
DKR Stadium case study: Erfahren Sie, wie Computer Vision den Umsatz und die Effizienz eines großen Sportstadions erheblich gesteigert hat.
-
Ecodesign for Sustainable Products Regulation (ESPR): Greifen Sie auf die offiziellen EU-Dokumente zur neuen Verordnung zu, die die digitale Transformation vorantreibt.
Computer Vision als Schlüssel zu einer nachhaltigen und effizienten Zukunft für Batterien
von Kevin Lancashire (Link zum Original-Text auf Englisch)
Blogbeitrag vom 8. August 2025

Von der Herstellung zum Digital Product Pass – Wie Computer Vision die Batterie-Wertschöpfungskette Revolutioniert.
In unserer dynamischen Welt, in der die Nachfrage nach Batterien exponentiell wächst, sind Effizienz, Qualität und Transparenz entlang der gesamten Wertschöpfungskette von entscheidender Bedeutung. Als Unternehmer und Wirtschaftsanalyst verfolge ich die Entwicklungen in diesem Sektor mit großem Interesse. Eine Technologie, die sich als bahnbrechend erweist, ist Computer Vision. Sie revolutioniert nicht nur Fertigungsprozesse, sondern legt auch den Grundstein für zukunftsweisende Ansätze wie den Digital Product Pass (DPP).
Precision and Quality: The Heart of Battery Production
Computer Vision ist weit mehr als nur eine Kamera am Fließband. Es handelt sich um ein intelligentes System, das visuelle Daten in Echtzeit erfasst, analysiert und interpretiert. In der Batterieproduktion führt dies zu einer beispiellosen Präzision. Anstelle von manuellen Stichproben werden nun alle Produkte einer 100-prozentigen Inline-Prüfung unterzogen.
Die Anwendungsbereiche sind vielfältig und decken alle kritischen Phasen ab::
-
Elektrodenproduktion: Die Systeme prüfen beschichtete Oberflächen auf kleinste Fehler, messen präzise die Breite und Geometrie von Schnitten und stellen sicher, dass nur fehlerfreie Komponenten in die nächste Stufe gelangen.
-
Zellmontage: Hier überwacht Computer Vision die exakte Ausrichtung von Anode, Kathode und Separator. Eine präzise Positionierung ist entscheidend für die Leistung und Sicherheit der Zellen und minimiert das Risiko von Kurzschlüssen.
-
Modul- und Pack-Montage: Diese Systeme führen Roboterarme mit millimetergenauer Präzision, um die Zellen zu positionieren. Außerdem überprüfen sie die Qualität von Schweißnähten und Klebeverbindungen – eine absolute Notwendigkeit für langlebige und sichere Batteriepacks.
Die unmittelbaren Vorteile liegen auf der Hand: geringere Ausschussraten, höhere Produktionsgeschwindigkeit und eine deutliche Steigerung der Produktsicherheit.
Die Brücke zum Digital Product Pass (DPP)
Der wahre strategische Wert von Computer Vision liegt jedoch in seiner Verbindung zu Rückverfolgbarkeit und Nachhaltigkeit. Die bevorstehende EU-Ökodesign-Norm für Batterien (DPP) erfordert eine lückenlose Dokumentation der Herkunft, der Inhaltsstoffe und der Herstellungsdetails jeder einzelnen Batterie.
Die von Computer-Vision-Systemen generierten Daten – von der Fehlerklassifizierung über Messdaten bis hin zur korrekten Montage – sind für diesen digitalen Pass unerlässlich. Sie liefern einen objektiven und überprüfbaren Nachweis für Qualität und die Einhaltung von Standards. Dies schafft Vertrauen bei den Verbrauchern und ermöglicht eine effiziente Kreislaufwirtschaft, indem der Zustand und die Zusammensetzung von Batterien für Recycling- oder Wiederverwendungszwecke transparent gemacht werden.
Ausblick und nächste Schritte
Für Unternehmen in diesem Sektor ist die Integration solcher Technologien ein entscheidender Erfolgsfaktor. Der Einsatz von Computer Vision ist nicht nur eine technische, sondern auch eine strategische Investition in die Zukunft.
Der nächste Schritt besteht darin, diese Datenströme zu verstehen und eine Plattform zu schaffen, die sie nicht nur speichert, sondern intelligent verknüpft und nutzbar macht. Der Fokus sollte darauf liegen, wie die gewonnenen Erkenntnisse in den Digital Product Pass integriert werden können, um den Kunden einen echten Mehrwert in Bezug auf Compliance, Nachhaltigkeit und Effizienz zu bieten.
Die Frage ist nicht, ob wir Computer Vision in der Batterieindustrie einsetzen sollten, sondern wie wir die damit gewonnenen Daten am besten nutzen können, um unsere Wachstumsprogramme voranzutreiben und eine führende Rolle in der Zukunft der Kreislaufwirtschaft zu übernehmen.
Hier sind einige Quellen, die den Zusammenhang zwischen Computer Vision und Batterien aus verschiedenen Perspektiven beleuchten.
1. Qualitätssicherung und Herstellung
Computer Vision in new battery factories – Ein Blogbeitrag von ATRIA Innovation über die Anwendung von Computer Vision zur Verbesserung der Qualität und Effizienz in der Batterieherstellung.
How Can Computer Vision Help in Battery manufacturing? – AEin Artikel von Ultralytics, der beschreibt, wie Computer-Vision-Modelle für die Fehlererkennung und präzise Montage eingesetzt werden.
Li-Ion batteries: 100% quality inspection along the entire process chain – Ein Technisches Dokument von Isra Vision, das die durchgängige Qualitätskontrolle bei der Herstellung von Lithium-Ionen-Batterien mithilfe von Bildverarbeitung erläutert.
2. Recycling and Kreislaufwirtschaft
Recent Advancements in Artificial Intelligence in Battery Recycling – Ein wissenschaftlicher Artikel, der die Rolle von KI und Computer Vision bei der Automatisierung der Sortierung, Klassifizierung und Demontage von Batterien beleuchtet.
Manchester AI expert helps local SME develop the technology to battle battery waste – Ein Nachrichtenartikel über ein System, das mithilfe fortschrittlicher Bildverarbeitung Lithium-Ionen-Batterien aus dem Abfallstrom erkennt und herausfiltert.
3. Digital Product Pass (DPP)
How Digital Product Passports Are Revolutionizing Battery Sustainability – Ein Blogbeitrag, der erklärt, wie DPPs detaillierte Informationen zu Materialien, Herstellungsprozessen und den Umweltauswirkungen von Batterien liefern, die eng mit den von Computer Vision erfassten Daten verknüpft sind.
The Digital Product Pass (DPP) ist eine der innovativsten Initiativen der Europäischen Union als teil des Eurepean Green Deal und der Kreislaufwirtschaft
Neueste Nachrichten und Innovationen im Bereich intelligentes Parken und Verkehrsanalyse (2025)
von Kevin Lancashire (Link zum Original-Text auf Englisch)

KI-gestützte Computer Vision, IoT-Sensoren und Deep Learning verändern das intelligente Parken und die Verkehrsanalyse im Jahr 2025 rasant. Dies hat zu wichtigen Innovationen und praktischen Anwendungen geführt.
1. KI und IoT revolutionieren die Parkplatzführung
Intelligente Parksysteme mit IoT-Sensoren und hochauflösenden Kameras werden weltweit eingeführt. Diese Systeme liefern den Fahrern Echtzeitdaten, leiten sie zu freien Parkplätzen und reduzieren Verkehrsstaus um bis zu 30 %.
Beispiel: Trikala, Griechenland, hat ein intelligentes Parksystem eingeführt, mit dem Nutzer über digitale Geldbörsen bezahlen können, was die Effizienz und den Komfort verbessert.
2. Computer Vision für die Verkehrsanalyse
Deep-Learning-Modelle (wie YOLOv8) zählen und klassifizieren Fahrzeuge aus Videoaufnahmen nun mit einer Genauigkeit von über 90 %.
Diese Technologie senkt die Kosten herkömmlicher Verkehrserhebungen und liefert wichtige Daten für die Stadtplanung und das Staumanagement.
3. Automatisierte Abrechnung und Sicherheit
Integrierte Bildverarbeitung und OCR ermöglichen die Echtzeit-Erkennung von Kennzeichen und die automatisierte Abrechnung, wodurch Fehler um 30 % reduziert und die Einnahmen der Betreiber um 20 % gesteigert werden.
Diese Lösungen verbessern auch die Durchsetzung und unterstützen nahtlose digitale Zahlungen und kontaktlosen Zugang.
4. Smart Parking als Teil des Smart City Grid
Smart Parking ist heute ein wichtiger Bestandteil des umfassenderen Smart City-Ökosystems. Parkdaten werden in städtische Mobilitätsplattformen und EV-Ladenetzwerke integriert, um den Verkehrsfluss zu steuern, den Energieverbrauch zu optimieren und die Nachhaltigkeit zu fördern.
5. Benutzererfahrung und Nachhaltigkeit
Mobile und cloudbasierte Apps bieten Autofahrern Echtzeit-Parkplatzsuche und Zahlungsoptionen.
Intelligente Parksysteme unterstützen auch umweltfreundliche Initiativen durch die Integration von EV-Ladeinfrastruktur.
Zusammenfassung: Im Jahr 2025 werden Smart Parking und Verkehrsanalyse dank KI und Computer Vision erhebliche Fortschritte machen. Diese Innovationen führen zu weniger Verkehr, geringeren Emissionen, höheren Einnahmen für Betreiber und einer grundlegenden Veränderung in der Art und Weise, wie Städte Mobilität und Stadtplanung verwalten. Nachträglich Links zu einigen der Quellen (Englisch)
-
Smart Parking 2025: Die 5 Innovationen, welche die urbane Mobilität verändern werden
-
2025 ANPR Guide – Wie Nummernschilderkennung moderne Abläufe revolutioniert
-
Global Smart Parking Systeme Markt Analyse 2025-2030: Wachstum
Weltweit führen Städte intelligente Park- und Verkehrsanalysesysteme ein. Hier sind einige Beispiele aus Ihrer Region und aus dem Ausland:
Beispiele in Europa und der Schweiz
-
Frauenfeld, Schweiz: Die Stadt führte zusammen mit dem Unternehmen Parquery AG ein Pilotprojekt für intelligentes Parken unter Verwendung von Bilderkennung durch. Daten zu verfügbaren Parkplätzen werden an eine App gesendet, um Autofahrern bei der Suche nach Parkplätzen zu helfen.
-
Kanton Zürich, Schweiz: Der Kanton veröffentlichte einen umfassenden Bericht über bewährte Verfahren für intelligentes Parken unter Verwendung von Bilderkennung, basierend auf der Fallstudie aus Frauenfeld. Dieser dient anderen Schweizer Städten als Leitfaden.
-
St. Gallen, Schweiz: Die Stadt startete ein Pilotprojekt für intelligentes Parken auf Basis eines LoRaWAN-Funknetzes (Long Range Wide Area Network) zur Verbindung von Parksensoren.
-
Santander, Spanien: Santander gilt als Pionier im Bereich Smart-City-Technologie. Seit 2009 wurden in der ganzen Stadt über 20.000 Sensoren installiert, um die Parkplatzbelegung zu überwachen und den Verkehr entsprechend umzuleiten.
-
Barcelona, Spanien: Die Stadt ist bekannt für ihre intelligente Verkehrssteuerung, die Staus reduziert und die Fahrzeiten verkürzt.
-
London, England: London nutzt bereits in einigen Bereichen intelligente Parklösungen mit Sensoren und verfügt über ein fahrerloses Nahverkehrssystem (Heathrow Pods) am Flughafen.
Internationale Beispiele
-
Miami-Dade, USA: Die Stadt nutzt ein „Advanced Traffic Management System (ATMS)”, das auf mobilen Routern basiert, um Staus und Verzögerungen zu reduzieren.
-
Songdo, Südkorea: In diesem Geschäftsviertel werden 300 interaktive Sicherheitskameras über eine Leitstelle überwacht.
-
Singapur: Die Stadt ist bekannt für ihre fortschrittlichen Nahverkehrssysteme, die stark auf Sensoren und Datenanalyse setzen.
Blogbeitrag vom 4. August 2025
Ihre Welt, smarter: Wie QR-Codes und Computer-Vision das Leben einfacher machen
von Kevin Lancashire (Link zum Original-Text auf Englisch)

Sie haben wahrscheinlich schon einmal einen QR-Code gescannt – vielleicht für eine Speisekarte im Restaurant, eine Konzertkarte oder um schnell eine Website zu besuchen. Diese praktischen Quadrate gibt es schon seit einiger Zeit und sie machen es einfach, Ihre physische Welt mit digitalen Informationen zu verbinden. Aber was wäre, wenn sie noch mehr könnten?
Dank einer leistungsstarken Partnerschaft mit Computer Vision – der Technologie, die Computern hilft, Bilder zu „sehen” und zu verstehen – bieten QR-Codes Ihnen nun ein neues Maß an Komfort, Transparenz und personalisierten Erlebnissen.
Mehr als nur ein Scan: Was haben Sie davon?
Stellen Sie sich Folgendes vor:
Intelligenter Einkaufen, weniger Aufwand
-
Sofortige Produktdetails: Scannen Sie einen QR-Code auf einem Produkt und erhalten Sie sofort umfassende Informationen zu dessen Herstellungsdetails, Herkunft oder Nachhaltigkeitsmaßnahmen. Kein Rätselraten mehr – Sie erhalten die Fakten, die Sie interessieren, direkt auf Ihrem Smartphone.
- Personalisierte Angebote: Der gleiche Scan kann Sonderangebote auslösen, die speziell auf Sie zugeschnitten sind, basierend auf Ihren Vorlieben oder früheren Einkäufen.
-
Virtuelles Anprobieren: Sie möchten neue Kleidung oder Möbel kaufen? Scannen Sie einen Code und nutzen Sie Augmented Reality (AR), um Artikel virtuell „anzuprobieren“ oder zu sehen, wie Möbel in Ihrer Wohnung aussehen, bevor Sie sie kaufen. Das stärkt Ihr Vertrauen und kann sogar Rückgaben reduzieren.
-
Schnelleres Bezahlen: In einigen Geschäften sorgt Computer Vision für ein nahtloses, kassenloses Einkaufserlebnis, sodass Sie sich die gewünschten Artikel nehmen und gehen können, ohne in der Schlange stehen zu müssen.
Beispiellose Transparenz und Vertrauen
-
Sofortige Produktdetails: Scannen Sie einen QR-Code auf einem Produkt und erhalten Sie sofort umfassende Informationen zu dessen Herstellungsdetails, Herkunft oder Nachhaltigkeitsmaßnahmen. Kein Rätselraten mehr – Sie erhalten die Fakten, die Sie interessieren, direkt auf Ihrem Smartphone.
-
Personalisierte Angebote: Der gleiche Scan kann Sonderangebote auslösen, die speziell auf Sie zugeschnitten sind, basierend auf Ihren Vorlieben oder früheren Einkäufen.
-
Virtuelles Anprobieren: Sie möchten neue Kleidung oder Möbel kaufen? Scannen Sie einen Code und nutzen Sie Augmented Reality (AR), um Artikel virtuell „anzuprobieren“ oder zu sehen, wie Möbel in Ihrer Wohnung aussehen, bevor Sie sie kaufen. Das stärkt Ihr Vertrauen und kann sogar Rückgaben reduzieren.
-
Schnelleres Bezahlen: In einigen Geschäften sorgt Computer Vision für ein nahtloses, kassenloses Einkaufserlebnis, sodass Sie sich die gewünschten Artikel nehmen und gehen können, ohne in der Schlange stehen zu müssen.
Das Fazit für Sie
Die Kombination aus Computer Vision und QR-Codes bedeutet ein besser informiertes, bequemeres und personalisierteres Erlebnis in Ihrem Alltag. Sie erhalten mehr Kontrolle über die Informationen, die Sie erhalten, profitieren von reibungsloseren Interaktionen und können darauf vertrauen, dass die von Ihnen ausgewählten Produkte Ihren Werten entsprechen. Es geht darum, Ihre Welt smarter zu machen, einen Scan nach dem anderen.
Weitere Informationen:
1. Computer vision – Wikipedia
2. Computer Vision Tutorial – GeeksforGeeks
3. How Do QR Codes Work?QR Code Technical Basics
5. How to Monetize Data: 2025 Data Monetization Strategies – Qrvey
6. QR Code possible data types or standards – Stack Overflow
7. Digitaler Produktepass – Der Schlüssel zur Transparenz und Nachhaltigkeit in der EU
Blogbeitrag vom 25. Juli 2025
Ihre nächste Mahlzeit: Von KI gesehen und verstanden?
von Kevin Lancashire (Link zum Original-Text auf Englisch)

Die einfache Smartphone-Kamera, einst ein Werkzeug für Urlaubsfotos, verändert nun still und leise unser Verständnis unserer täglichen Ernährung. Jahrelang war das Aufzeichnen unserer Ernährung eine mühsame Angelegenheit, die oft mit Fehlern und Vergesslichkeit behaftet war. Doch eine neue Welle der Computer-Vision-Technologie beginnt nun, eine objektivere Sichtweise zu bieten.
Dieses sich entwickelnde Gebiet, in dem künstliche Intelligenz lernt, Lebensmittel zu „sehen” und zu interpretieren, verspricht, über die Subjektivität traditioneller Ernährungstagebücher hinauszugehen. Es entstehen Systeme, die Lebensmittel erkennen, Portionsgrößen schätzen und sogar den Nährstoffgehalt direkt aus einem Foto berechnen können. Anwendungen wie SnapCalorie zeigen, wie mobile Technologien nahezu in Echtzeit Einblicke in die Ernährung liefern können, wodurch Einzelpersonen potenziell in die Lage versetzt werden, mit weniger Aufwand fundiertere Entscheidungen zu treffen. Die Entwicklung umfassender Datensätze wie Nutrition5k erweist sich als entscheidend für das Training dieser hochentwickelten Modelle des maschinellen Lernens.
Der Weg zur breiten Akzeptanz ist jedoch nicht ohne Schwierigkeiten. Die Genauigkeit, insbesondere bei der Schätzung von Portionsgrößen, bleibt eine große Hürde; selbst geschulte Experten haben damit Schwierigkeiten. Angesichts der Notwendigkeit einer kontinuierlichen Bildaufnahme gibt es auch berechtigte Bedenken hinsichtlich des Datenschutzes. Darüber hinaus hängt die Wirksamkeit dieser Systeme stark von der Vielfalt und Qualität ihrer Trainingsdaten ab, und eine Verzerrung zugunsten bestimmter Lebensmittelarten könnte zu weniger zuverlässigen Ergebnissen für andere führen. Laufende Forschung ist unerlässlich, um diese Algorithmen zu verfeinern und ihre Zuverlässigkeit unter den vielfältigen Bedingungen des Alltags sicherzustellen.
Die Technologie befindet sich zwar noch in der Entwicklung, doch die potenziellen Vorteile für die öffentliche Gesundheit und die individuelle Ernährungssteuerung liegen auf der Hand. Dieser Übergang von manuellen, oft ungenauen Methoden zu einem stärker datengestützten Ansatz könnte ein wertvolles Instrument zur Förderung gesünderer Ernährungsgewohnheiten in verschiedenen Bevölkerungsgruppen sein. Der Weg dorthin erfordert kontinuierliche Innovation und eine sorgfältige Abwägung sowohl der technischen als auch der ethischen Dimensionen, um die Wirkung wirklich zu maximieren.
Hier sind die Quellen, auf denen der Newsletter basiert:
Computer Vision for Food Quality Assessment: Advances and Challenges
SnapCalorie AI Calorie Counter (Google Play Store)
Blogbeitrag vom 18. Juli 2025
Computer Vision und KI: Revolutionierung der Patientenüberwachung
von Kevin Lancashire (Link zum Original-Text auf Englisch)
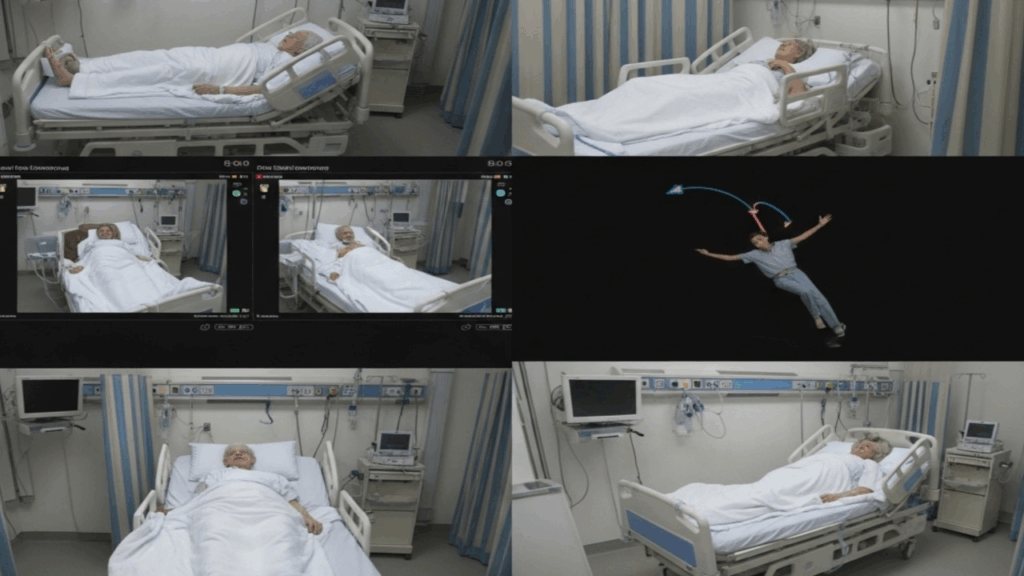
Computer-Vision-Systeme, die häufig RGB-Videos nutzen, die von in Patientenzimmern installierten Kameras aufgenommen werden, liefern zunehmend Echtzeit-Einblicke in das Verhalten, die Bewegungen und Interaktionen von Patienten. Diese hochentwickelten Systeme verwenden fortschrittliche Modelle, beispielsweise auf Basis der YOLOv4-Architektur, für eine präzise Objekterkennung und identifizieren wichtige Elemente wie „Person“, „Bett“ und „Stuhl“ innerhalb der überwachten Umgebung. Die Bewegungsschätzung erfolgt mithilfe von Algorithmen wie dem dichten optischen Fluss nach Gunnar-Farneback, der die horizontale und vertikale Verschiebung für jedes Pixel zwischen aufeinanderfolgenden Bildern berechnet und so einen Indikator für die Aktivitätsintensität liefert.
Durch die Analyse dieser detaillierten Datenströme kann die KI übergeordnete Metriken verfolgen, wie z. B. den Status „Patient allein“ – der die Abwesenheit von Pflegepersonal in einer definierten Nähe zum Patienten anzeigt. Diese Metrik ist ein wichtiger Indikator für die Bewertung des Sturzrisikos und die Identifizierung unbeaufsichtigter Bewegungen und geht über die einfache Erkennung hinaus bis hin zur kontinuierlichen Analyse der Aktivitätsintensität und Trends im Zeitverlauf. Die Fähigkeit dieser Systeme, solche Indikatoren zuverlässig und mit nachgewiesener Genauigkeit zu verfolgen, erhöht die Sicherheit erheblich, da sie die Erkennung von Risiken (z. B. Patienten, die unbeaufsichtigt ihr Bett verlassen) ermöglicht, die bei regelmäßigen Untersuchungen möglicherweise übersehen werden.
Computer-Vision-Systeme, die häufig RGB-Videos nutzen, die von in Patientenzimmern installierten Kameras aufgenommen werden, liefern zunehmend Echtzeit-Einblicke in das Verhalten, die Bewegungen und Interaktionen von Patienten. Diese hochentwickelten Systeme verwenden fortschrittliche Modelle, beispielsweise auf Basis der YOLOv4-Architektur, für eine präzise Objekterkennung und identifizieren wichtige Elemente wie „Person“, „Bett“ und „Stuhl“ innerhalb der überwachten Umgebung. Die Bewegungsschätzung erfolgt mithilfe von Algorithmen wie dem dichten optischen Fluss nach Gunnar-Farneback, der die horizontale und vertikale Verschiebung für jedes Pixel zwischen aufeinanderfolgenden Bildern berechnet und so einen Indikator für die Aktivitätsintensität liefert.
Durch die Analyse dieser detaillierten Datenströme kann die KI übergeordnete Metriken verfolgen, wie z. B. den Status „Patient allein“ – der die Abwesenheit von Pflegepersonal in einer definierten Nähe zum Patienten anzeigt. Diese Metrik ist ein wichtiger Indikator für die Bewertung des Sturzrisikos und die Identifizierung unbeaufsichtigter Bewegungen und geht über die einfache Erkennung hinaus bis hin zur kontinuierlichen Analyse der Aktivitätsintensität und Trends im Zeitverlauf. Die Fähigkeit dieser Systeme, solche Indikatoren zuverlässig und mit nachgewiesener Genauigkeit zu verfolgen, erhöht die Sicherheit erheblich, da sie die Erkennung von Risiken (z. B. Patienten, die unbeaufsichtigt ihr Bett verlassen) ermöglicht, die bei regelmäßigen Untersuchungen möglicherweise übersehen werden.
Fortschrittliche Anwendungen in der Fernüberwachung von Patienten
Computer Vision revolutioniert die Fernüberwachung von Patienten (Remote Patient Monitoring, RPM), indem sie fortschrittliche, unauffällige Überwachungsfunktionen direkt in die Patientenumgebung bringt und das Gesundheitswesen zu einem proaktiveren und umfassenderen Ansatz führt.
-
Bewegungs- und Haltungsanalyse: Computer-Vision-Systeme, die häufig RGB-Videos von Kameras verwenden, analysieren das Verhalten, die Bewegungen und die Interaktionen von Patienten in Echtzeit. Sie können kritische Ereignisse wie Stürze oder unbeaufsichtigte Bewegungen erkennen, indem sie Objekte wie „Person“, „Bett“ und „Stuhl“ identifizieren und eine Bewegungsschätzung durchführen. Diese kontinuierliche Analyse der Aktivitätsintensität und der Trends im Zeitverlauf erhöht die Patientensicherheit erheblich, indem sie Risiken aufzeigt, die bei regelmäßigen Kontrollen möglicherweise übersehen werden. Für einen Gartenliebhaber wie Sie, der gerne schneidet und pflegt, könnte dies mit der kontinuierlichen Überwachung der Gesundheit Ihrer Pflanzen auf frühe Anzeichen von Stress vergleichbar sein, anstatt sie nur gelegentlich zu überprüfen.
-
Berührungslose Überwachung der Vitalfunktionen: Über die Bewegung hinaus kann Computer Vision, insbesondere durch Remote-Photoplethysmographie (rPPG), winzige Veränderungen der Gesichtsfarbe aufgrund des Blutflusses erkennen, um Pulsfrequenz und Blutdruck zu bestimmen, und das alles ohne physischen Kontakt. Diese Methode erhöht den Komfort für den Patienten und verringert das Infektionsrisiko, wodurch sie sich ideal für gefährdete Bevölkerungsgruppen eignet.
-
Analyse von Gesichtsausdrücken zur Erkennung von Stress: Mithilfe von KI und Deep Learning kann Computer Vision subtile Gesichtsausdrücke analysieren, um Anzeichen von Schmerzen, Stress oder anderen emotionalen Zuständen zu erkennen, selbst wenn Patienten nicht verbal kommunizieren können. Dies ist besonders wertvoll für Säuglinge, schwerkranke Menschen oder Menschen mit kognitiven Beeinträchtigungen, da es eine objektive Beurteilung subjektiver Zustände ermöglicht.
-
Multimodale KI für ganzheitliche Einblicke: Die wahre Leistungsfähigkeit zeigt sich, wenn Computer-Vision-Daten durch multimodale KI mit anderen Quellen wie Wearables und Umgebungssensoren integriert werden. Dies ermöglicht einen umfassenderen Überblick über die Gesundheit des Patienten und ermöglicht hochpräzise Analysen und proaktive Interventionen, bevor sich eine Krise manifestiert.
Durch kontinuierliche, unauffällige Überwachung und tiefe Einblicke in physiologische und Verhaltensmuster macht Computer Vision RPM effektiver, erhöht die Patientensicherheit und trägt zu einer personalisierteren und zugänglicheren Gesundheitslandschaft bei.
Quellen:
- Remote Patient Monitoring: The Complete Guide – Health Recovery Solutions, accessed July 18, 2025, https://www.healthrecoverysolutions.com/remote-patient-monitoring
- What is Remote Patient Monitoring and Why is it Transforming Healthcare? – Medixine, accessed July 18, 2025, https://medixine.com/what-is-remote-patient-monitoring/
- Telehealth and Remote Patient Monitoring Innovations in Nursing Practice: State of the Science | OJIN, accessed July 18, 2025, https://ojin.nursingworld.org/table-of-contents/volume-28-2023/number-2-may-2023/special-topic-nursing-now/telehealth-and-remote-patient-monitoring/
- Continuous Versus Intermittent Vital Signs Monitoring Using a Wearable, Wireless Patch in Patients Admitted to Surgical Wards – PubMed Central, accessed July 18, 2025, https://pmc.ncbi.nlm.nih.gov/articles/PMC6305881/
- Continuous Patient Monitoring in Healthcare: A Comprehensive Review of Opportunities, Challenges, and Future Directions – ResearchGate, accessed July 18, 2025, https://www.researchgate.net/publication/393564686_Continuous_Patient_Monitoring_in_Healthcare_A_Comprehensive_Review_of_Opportunities_Challenges_and_Future_Directions
- What Are The Benefits Of Remote Patient Monitoring For Hospitals? – Consensus Academic Search Engine, accessed July 18, 2025, https://consensus.app/questions/what-benefits-remote-patient-monitoring-hospitals/
- Shaping the Future of Healthcare: AI Patient Monitoring – Ambula EMR system, accessed July 18, 2025, https://www.ambula.io/shaping-the-future-of-healthcare-ai-patient-monitoring/
- Remote Patient Monitoring Is Making Healthcare More Accessible Than Ever In The Digital Age – Blog, accessed July 18, 2025, https://blog.pqegroup.com/gxp-compliance/remote-patient-monitoring-is-making-healthcare-more-accessible-than-ever-in-the-digital-age
- Key Fundamentals and Examples of Sensors for Human Health: Wearable, Non-Continuous, and Non-Contact Monitoring Devices – MDPI, accessed July 18, 2025, https://www.mdpi.com/1424-8220/25/2/556
- 5 Benefits of Remote Patient Monitoring – KORE Wireless, accessed July 18, 2025, https://www.korewireless.com/blog/5-benefits-of-remote-patient-monitoring/
- Remote Vital Sensing in Clinical Veterinary Medicine: A … – MDPI, accessed July 18, 2025, https://www.mdpi.com/2076-2615/15/7/1033
Blogbeitrag vom 10. Juli 2025
Ihre Welt durch die KI-Linse: Was Smartphone Vision-Daten für Sie bedeuten
von Kevin Lancashire (Link zum Original-Text auf Englisch) Dieser Text wurde leicht redigiert

Ihr Smartphone, ausgestattet mit KI, verarbeitet mithilfe seiner Kamera und Sensoren ständig die Welt um Sie herum. Dabei geht es nicht nur um coole Funktionen, sondern um eine grundlegende Veränderung Ihrer Interaktionen, Ihrer Privatsphäre und sogar Ihrer Wahrnehmung.
Für Ihren Alltag und Ihren Komfort
-
Intelligentere Interaktionen: Ihr Smartphone kann jetzt beispielsweise Objekte, die Sie sehen, sofort identifizieren – eine Pflanze im Garten (auch wenn Sie sich nicht an ihren genauen Namen erinnern bekommen Sie ihn vom Telefon!), ein Restaurantschild oder Text auf einem Dokument. Es kann dann sofortige Aktionen anbieten, wie z. B. Details nachschlagen, Text übersetzen oder sogar direkt aus dem, was es „sieht“, einen Kalendertermin erstellen.
-
Mehr Kreativität: Mit der KI-gestützten Funktion „Clean Up” in Fotos können Sie unerwünschte Elemente nahtlos aus Ihren Bildern entfernen. Mit den neuen Funktionen „Genmoji” und „Image Wand” können Sie personalisierte visuelle Inhalte erstellen, indem Sie diese einfach beschreiben, oder eine grobe Skizze in ein ausgefeiltes Bild verwandeln.
-
Optimierte Kommunikation: Ihr Smartphone kann beispielsweise lange E-Mails oder Audio-Transkriptionen zusammenfassen und Ihnen so helfen, den Überblick zu behalten. Es schlägt intelligente Antworten in Nachrichten vor und spart Ihnen Zeit.
-
Personalisierte Gesundheit: Ihr Smartphone wird zunehmend zu einem persönlichen Gesundheitsmonitor, der mithilfe seiner Kamera und anderer Sensoren Vitalparameter oder Schlafmuster verfolgt. Das bedeutet personalisiertere Wellness-Empfehlungen und eine Verlagerung hin zur Vorsorge für Sie.
-
Intuitives Einkaufen: Mit der „visuellen Suche” können Sie Ihre Kamera auf einen Artikel in einem Geschäft richten und sofort ähnliche Produkte online finden. Dies verändert die Art und Weise, wie Sie Dinge entdecken und kaufen, und macht das Einkaufen unmittelbarer.
Für Ihre Privatsphäre & Identität
-
Das „Datenschutzparadoxon”: Während Apple zur Wahrung Ihrer Privatsphäre Wert auf die Verarbeitung auf dem Gerät legt (was bedeutet, dass die Rohdaten oft auf Ihrem Smartphone verbleiben), bedeutet die schiere Menge der von Ihnen generierten visuellen Daten, dass Ihr Gerät ständig Ihre Welt interpretiert. Auch wenn einzelne Daten nicht immer weitergegeben werden, können aus den aggregierten Mustern von Millionen von Nutzern dennoch Verhaltensweisen oder Präferenzen abgeleitet werden. Das bedeutet, dass Sie sich bewusst sein müssen, dass selbst die lokale Verarbeitung zu einem größeren, komplexen Datenökosystem beitragen kann.
-
Algorithmische Verzerrung in Ihrem Feed: Die von Millionen von Nutzern, darunter auch Ihnen, gesammelten visuellen Daten trainieren die KI. Wenn diese Daten gesellschaftliche Verzerrungen enthalten (z. B. bei der Gesichtserkennung, wie wir bei höheren Fehlerquoten für bestimmte Bevölkerungsgruppen gesehen haben), können diese Verzerrungen verstärkt werden und die Interaktionen der KI mit Ihnen beeinflussen. Dies kann sich auf alles auswirken, von gezielten Werbeanzeigen bis hin zur Art und Weise, wie Sie in Sicherheitssystemen identifiziert werden.
-
Vermittelte Realität und Selbstwahrnehmung: Die ständige Verwendung von visuellen KI-Filtern in sozialen Medien kann zu unrealistischen Schönheitsidealen führen. Wenn Sie sich selbst oder andere durch diese Filter sehen, kann dies Ihre Selbstwahrnehmung verzerren, den sozialen Vergleich verstärken und eine Diskrepanz zwischen Ihrem realen und Ihrem digitalen Selbst schaffen, was möglicherweise Ihre Authentizität untergräbt.
-
Vertrauen in das, was Sie sehen: Der Aufstieg von „Deepfakes“ – hyperrealistischen, von KI generierten Videos – macht es Ihnen schwerer, online zu unterscheiden, was echt und was gefälscht ist. Dies stellt Ihre Fähigkeit, visuellen Informationen zu vertrauen, auf die Probe und kann zu einer „postfaktischen“ Umgebung beitragen, in der es immer schwieriger wird, Fakten zu erkennen.
Für Ihre Fähigkeiten und Ihre Zukunft
-
Sich wandelnde Anforderungen an Ihre Fähigkeiten: Da KI sowohl einfache als auch komplexe visuelle Aufgaben automatisiert, müssen Sie Ihre Fähigkeiten anpassen. Der wirtschaftliche Wert wird zunehmend davon abhängen, wie Sie mit KI zusammenarbeiten und spezialisierte KI-Aufsichtsrollen entwickeln. Das bedeutet, dass kontinuierliches Lernen nicht nur ein Bonus ist, sondern für Ihre berufliche Relevanz unerlässlich ist.
Im Wesentlichen bieten die visuellen Funktionen Ihres Smartphones unglaublichen Komfort und neue Möglichkeiten, mit der Welt zu interagieren, aber sie erfordern auch Ihr achtsames Engagement und ein ausgeprägtes Bewusstsein dafür, wie Ihre Daten verwendet werden und wie KI Ihre Wahrnehmung und Privatsphäre beeinflussen kann.
Quellen
How AI is Shaping the Future of Smartphones | The AI Journal
10 Computer Vision Applications for 2025 | DigitalOcean
Blogbeitrag vom 6. Juli 2025
Das algorithmische Auge auf dem Wohlergehen
von Kevin Lancashire (Link zum Original-Text auf Englisch)

Computer Vision, einst weitgehend auf die akademische Forschung beschränkt, liefert heute greifbare Vorteile in verschiedenen Gesundheitsanwendungen. Von der Früherkennung von Krankheiten über die Unterstützung der Rehabilitation bis hin zur Optimierung von Fitnessprogrammen bietet diese Technologie Echtzeitüberwachung und personalisiertes Feedback. Sie stellt einen erheblichen Fortschritt dafür dar, Menschen ihre Gesundheit verwalten und wie medizinisches Fachpersonal Gesundheitsleistungen erbringt.
Die Verbreitung von Wearable-Technologie – Smartwatches und Fitness-Tracker, deren Marktvolumen mittlerweile auf unglaubliche 100 Milliarden Dollar geschätzt wird – hat diese Entwicklung massgeblich beschleunigt. Diese allgegenwärtigen Geräte sammeln riesige Mengen an biometrischen Daten, von der Herzfrequenz bis zum Aktivitätsniveau, die dann durch fortschrittliche Algorithmen in anwendbare Erkenntnisse umgewandelt werden. Es ist das digitale Äquivalent zu einem persönlichen Gesundheitsberater, der einem ständig zur Seite steht.
Diese transformative Kraft bringt jedoch auch gewisse Komplexitäten mit sich. Als Liberaler bin ich der festen Überzeugung, dass ethische Überlegungen zum Datenschutz und zu algorithmischen Verzerrungen von grösster Bedeutung sind. Die schiere Menge an sensiblen persönlichen Gesundheitsdaten, die verarbeitet werden, erfordert strenge Aufmerksamkeit für Sicherheit und transparente Datenpraktiken, um die Einhaltung von Vorschriften wie der DSGVO zu gewährleisten. Debatten über die Genauigkeit von Daten und das Potenzial für algorithmische Diskriminierung unterstreichen die Notwendigkeit robuster ethischer Rahmenbedingungen für die Entwicklung von KI.
Eine kurze Geschichte von Sehvermögen und Bytes
Die Entwicklung der Computervision im Gesundheits- und Fitnessbereich reicht bis in die Anfänge der Kybernetik und Robotik zurück. Was als theoretisches Konzept begann, hat sich durch Durchbrüche im Bereich des Deep Learning und die Verfügbarkeit riesiger Datensätze zu praktischen Lösungen für reale Probleme entwickelt. Der Fortschritt von der einfachen Bildverarbeitung hin zu ausgefeilter Objekterkennung und Bewegungserfassung bedeutet eine tiefgreifende Veränderung in der Art und Weise, wie Maschinen visuelle Informationen interpretieren.
Diese Entwicklung hat tiefgreifende Auswirkungen auf das Gesundheitswesen gehabt, die Diagnosegenauigkeit verbessert und sogar minimalinvasive chirurgische Eingriffe erleichtert. Im Fitnessbereich haben diese Fortschritte den Zugang zu Gesundheitsdienstleistungen demokratisiert und innovative Ansätze zur Fortschrittsverfolgung und frühzeitigen Risikoerkennung ermöglicht. Dies signalisiert einen breiteren Trend zur Nutzung künstlicher Intelligenz, um die Gesundheitsergebnisse zu verbessern und das Engagement der Nutzer für Wellness-Aktivitäten zu vertiefen.
Die technologischen Grundlagen
Im Kern basiert Computer Vision auf einer Reihe ausgefeilter Technologien:
-
Bildverarbeitung: Techniken zur Verfeinerung von visuellen Rohdaten, einschliesslich Rauschunterdrückung und Segmentierung, sind entscheidend für die Isolierung relevanter Informationen – sei es eine krebsartige Läsion oder eine Fehlstellung eines Gelenks.
-
Datenerfassung: Die anfängliche Erfassung visueller Informationen stützt sich auf fortschrittliche medizinische Bildgebungsgeräte wie MRT- und CT-Scanner sowie auf die immer leistungsfähigeren Kameras, die in Unterhaltungselektronikgeräten eingebaut sind.
-
Merkmalsextraktion: Dieser wichtige Schritt umfasst die Identifizierung und Quantifizierung hervorstechender Merkmale in Bildern, wobei visuelle Muster in eine mathematische Sprache umgewandelt werden, die von Algorithmen für maschinelles Lernen interpretiert werden kann.
-
Algorithmen für maschinelles Lernen: Dies sind die Analyse-Engines, die Muster klassifizieren und erkennen. Herkömmliche Methoden wie Support Vector Machines sind nach wie vor relevant, aber der eigentliche Paradigmenwechsel kam mit Convolutional Neural Networks (CNNs). Diese Deep-Learning-Architekturen zeichnen sich durch hervorragende Bilderkennung aus und zeigen bemerkenswerte Effizienz bei Aufgaben, die von der medizinischen Diagnose bis zur Haltungsanalyse reichen.
Da sich diese Technologien rasant weiterentwickeln, wird die Notwendigkeit robuster regulatorischer Rahmenbedingungen für Datenschutz, Algorithmentransparenz und Genauigkeitsstandards immer dringlicher.
Anwendungen und ihre Auswirkungen
Die praktischen Anwendungsmöglichkeiten von Computer Vision im Gesundheits- und Fitnessbereich sind vielfältig:
-
Wearables: Diese allgegenwärtigen Geräte liefern Echtzeitdaten zum physiologischen Zustand des Nutzers und lassen sich nahtlos in den Alltag integrieren.
-
KI-gestützte Personalisierung: KI-Algorithmen können Gesundheitsdaten synthetisieren, um massgeschneiderte Trainingsprogramme zu erstellen, die Aktivitätsprotokollierung zu automatisieren und eine Leistungsanalyse in Echtzeit anzubieten. Dieser spielerische Ansatz verbessert die Einhaltung und Wirksamkeit.
-
Online-Coaching: Virtuelle Plattformen nutzen Daten von Wearables, um Nutzer mit Remote-Trainern zu verbinden und so einen personalisierteren und datengestützten Ansatz für die Fitnessberatung zu fördern.
-
Bewegungsanalyse: Detaillierte Bewertungen der Körperhaltung und der Trainingsform sind für die Rehabilitation von unschätzbarem Wert und ermöglichen es Therapeuten, massgeschneiderte Rehabilitationsprogramme zu verschreiben.
-
Fernüberwachung: Über die Fitness hinaus kann Computer Vision auf nicht-invasive Weise Vitalparameter und subtile physiologische Veränderungen verfolgen und so eine kontinuierliche Patientenüberwachung bei chronischen Erkrankungen ermöglichen.
-
Diagnostische Präzision: Fortschrittliche Algorithmen reduzieren das Potenzial für menschliche Fehler bei Gesundheitsbewertungen und führen zu zuverlässigeren Diagnosen.
Die Zukunft gestalten
Trotz des transformativen Potenzials ist der Weg in die Zukunft nicht ohne Hindernisse:
-
Datenschutz: Die Sensibilität von Gesundheitsdaten erfordert strenge Protokolle, um Verstösse und Missbrauch zu verhindern.
-
Algorithmische Verzerrung: Nicht repräsentative Trainingsdaten können zu diskriminierenden Ergebnissen führen, was die Notwendigkeit einer ethischen KI-Entwicklung und einer strengen Validierung unterstreicht.
-
Vertrauen und Akzeptanz: Das Vertrauen der Öffentlichkeit in KI-gestützte Gesundheitslösungen ist für eine breite Akzeptanz von entscheidender Bedeutung und erfordert Transparenz und einen klaren Nachweis der Vorteile.
-
Interdisziplinäre Zusammenarbeit: Die Überbrückung der Kluft zwischen Informatik und Gesundheitswesen ist für die Entwicklung innovativer und effektiver Lösungen unerlässlich.
Die Entwicklung der Computer Vision im Gesundheits- und Fitnessbereich deutet auf eine immer tiefere Integration von KI und maschinellem Lernen hin. Die zu erwartenden Fortschritte versprechen eine verbesserte Diagnosegenauigkeit, hyper-personalisierte Fitnesserlebnisse und eine optimierte Kommunikation zwischen Nutzern und Gesundheitsdienstleistern. Für den Markt selbst wird ein erhebliches Wachstum prognostiziert, mit Schätzungen, die einen Anstieg auf 3,1 Milliarden US-Dollar bis Ende 2025 nahelegen.
Als jemand, der sich für Zusammenarbeit einsetzt und Technologie zum Aufbau von Plattformen nutzt, glaube ich, dass diese Konvergenz enorme Chancen für den gesellschaftlichen Nutzen bietet. Die Branche muss jedoch verantwortungsbewusst mit den Komplexitäten des Datenschutzes und ethischen Überlegungen umgehen, um das Potenzial dieser bahnbrechenden Technologie voll auszuschöpfen. Welche neuen Dimensionen könnte dies für das Schweizer Gesundheitswesen mit sich bringen?
Referenzen
https://digitalhealth.folio3.com/blog/computer-vision-in-healthcare-benefits-challenges-applications/
https://blog.unitlab.ai/computer-vision-in-healthcare-applications-benefits-and-challenges/
https://www.arkasoftwares.com/blog/ai-in-fitness-apps-use-cases-benefits-challenges/
Blogbeitrag vom 27. Juni 2025
Google AI Studio: Die Verwandlung der Computer Vision für Schweizer Startups
von Kevin Lancashire (Link zum Original-Text auf Englisch)
Das Aufkommen leistungsstarker, leicht zugänglicher Tools wie Google AI Studio verändert die Landschaft der Computer Vision, insbesondere für junge Unternehmen in der Schweiz, grundlegend. Es ist nicht nur ein potentes Werkzeug, sondern ein strategischer Wegbereiter, der beispiellose Möglichkeiten für Innovation und Marktdisruption eröffnet – besonders relevant angesichts des Bestrebens der Schweiz, trotz einer Implementierungslücke eine Führungsrolle im Bereich KI einzunehmen.
Der Vorteil von Studio: Beschleunigte Innovation für Schweizer Unternehmen
Für Start-ups im Bereich Computer Vision bietet Google AI Studio drei entscheidende Vorteile, die direkt auf die üblichen Hürden eingehen, mit denen Schweizer KMU konfrontiert sind:
-
Schnelle Prototypenerstellung und Iteration: Vorbei sind die Zeiten, in denen riesige, vorab gekennzeichnete Datensätze und teure Hardware im Voraus benötigt wurden. Studio ermöglicht eine sofortige Bildanalyse, sodass sich Start-ups auf ihre Kernideen konzentrieren können, anstatt sich mit Infrastruktur oder grundlegenden Algorithmen herumzuschlagen. Diese Agilität, die in der heutigen schnelllebigen Tech-Umgebung entscheidend und für ein agiles IT-Management unerlässlich ist, ermöglicht die schnelle Erstellung, das Testen und die iterative Verfeinerung von Minimum Viable Products (MVP).
-
Modernste Modelle zur Hand: Der Zugriff auf die umfangreiche Bibliothek vorab trainierter Modelle von Google bedeutet, dass Analysen vom ersten Tag an präzise und zuverlässig sind, selbst bei begrenzten proprietären Daten. Komplexe Aufgaben – von der Objekterkennung und Bildklassifizierung bis hin zur Gesichtserkennung und dem Verständnis komplexer Inhalte – werden zu „Out-of-the-Box“-Funktionen oder lassen sich leicht anpassen. Diese Fähigkeit unterstützt die Entwicklung von „Schweizer Versionen” von KI-Modellen, die auf spezifische lokale Anforderungen zugeschnitten sind, ohne dass sie von Grund auf neu erstellt werden müssen.
-
Kosteneffizienz und Skalierbarkeit: Die Eintrittsbarriere wird drastisch gesenkt. Startups sparen erhebliche Kapitalkosten, die sonst in Hardware, Softwarelizenzen und spezialisiertes Personal investiert werden müssten – ein entscheidender Faktor angesichts der Unsicherheit hinsichtlich der Kosten, die bei Schweizer KMUs vorherrscht. Google AI Studio bietet eine großzügige kostenlose Stufe und flexible Pay-as-you-go-Tarife, wodurch die Kosten skalierbar und vorhersehbar sind. So können Schweizer Start-ups fortschrittliche Funktionen nutzen, ohne die üblicherweise erforderlichen hohen Anfangsinvestitionen tätigen zu müssen.
Die disruptive Welle: Auswirkungen auf die Schweizer Industrie
Die Konvergenz dieser Funktionen läutet eine disruptive Ära ein, fördert Innovationen in verschiedenen Sektoren und hilft Schweizer Unternehmen, ihre strategischen KI-Ziele in messbare Ergebnisse umzusetzen.
-
Personalisierte Erlebnisse: Stellen Sie sich eine Gartenplanungs-App vor, die anhand eines einfachen Fotos Pflanzenarten identifizieren kann (sogar solche wie Sonnenblumen oder Tulpen, deren Namen Sie nicht mehr genau wissen) und dann maßgeschneiderte Pflegehinweise oder Gestaltungsvorschläge anbietet. Solche Funktionen lassen sich auch auf Online-Shops übertragen, die durch die Analyse von nutzergenerierten Bildern hyper-personalisierte Produktempfehlungen liefern.
-
Effizienz in traditionellen Branchen: In der Fertigung, wo die Schweiz bei der Roboterdichte führend ist (3.876 Roboter pro 10.000 Fabrikarbeiter in der Automobilindustrie im Jahr 2023) und eine Produktivitätssteigerung von 52 % durch Computer Vision erwartet, kann Google AI Studio die Qualitätskontrolle ermöglichen, um winzige, für das menschliche Auge unsichtbare Fehler zu erkennen. In der Landwirtschaft kann die Analyse von Drohnenbildern von Feldern auf Pflanzengesundheit und Schädlingsbefall erfolgen, während das Gesundheitswesen durch die Analyse medizinischer Bilder zur Diagnoseunterstützung profitiert.
-
Neue Geschäftsmodelle: Diese Zugänglichkeit fördert neuartige Unternehmungen: KI-gestützte Sicherheitssysteme, die verdächtiges Verhalten in Echtzeit erkennen; automatisierte Inhaltsmoderation, die unerwünschte Inhalte auf Plattformen filtert; und intelligente Bestandsverwaltungssysteme, die die Lagerbewirtschaftung in Lagerhäusern oder im Einzelhandel rationalisieren.
-
Verbesserte Kreativität und Unterhaltung: Automatischer Stilübertrag, Inhaltsgenerierung und intelligente Filter in der Bild- und Videobearbeitung werden weit verbreitet. Augmented-Reality-Erlebnisse (AR) werden durch eine verbesserte Umgebungserkennung immer immersiver.
Dank der Demokratisierung dieser Technologie können Start-ups mit innovativen Ideen schnell in den Markt eintreten und etablierte Akteure herausfordern. Erfolg hängt immer weniger von massiven Kapitalreserven ab, sondern vielmehr von Kreativität und der intelligenten Anwendung verfügbarer Tools. Dieser Ansatz stützt die Erkenntnis, dass KI in erster Linie „61 % der Schweizer Arbeitskräfte ergänzt” und eher eine Erweiterung als eine einfache Substitution darstellt – eine wichtige Überlegung für den einzigartigen Arbeitsmarkt der Schweiz.
Blogbeitrag vom 20. Juni 2025
Was ist undicht? Die unsichtbare Bedrohung für unsere globalen Lebensadern
von Kevin Lancashire (Link zum Original-Text auf Englisch)

Die Pipelines der Welt sind die unsichtbaren Arterien unserer globalen Wirtschaft, die still und leise lebenswichtige Ressourcen über Kontinente hinweg transportieren. Doch wie jedes Rohr-Transportsystem sind auch sie anfällig für Lecks – ein heimtückisches Problem mit verheerenden Folgen für Umwelt, Finanzen und Sicherheit. Viel zu lange war die Erkennung dieser Lecks eine reaktive, kostspielige und oft zerstörerische Angelegenheit. Aber was wäre, wenn wir das Unsichtbare „sehen” und Katastrophen verhindern könnten, bevor sie eintreten?
Das Problem ist gravierend: Durch Rohrleitungsbrüche werden schädliche Substanzen freigesetzt, die die Treibhausgasemissionen (insbesondere Methan) in die Höhe treiben und unser kostbares Wasser und unseren Boden verschmutzen. Wirtschaftlich gesehen sind die Folgen hohe Bußgelder, Betriebsstilllegungen, erhebliche Produktverluste und exorbitante Reparaturkosten. Bedenken Sie Folgendes: Globale Studien zeigen, dass allein die Wasserverluste aus Verteilungsnetzen zwischen alarmierenden 10 % und 40 % liegen können. Dabei geht es nicht nur um Produktverluste, sondern um eine grundlegende Bedrohung der wirtschaftlichen Stabilität und des öffentlichen Wohlstands.
Hier kommen Infrarot (IR) und Wärmebildtechnik ins Spiel. Dabei handelt es sich nicht um eine neue Spielerei, sondern um eine bahnbrechende Lösung, die die Prinzipien der Wärmestrahlung nutzt, um das sonst Unwahrnehmbare zu erkennen. Durch die Erkennung subtiler Temperaturschwankungen – sei es durch ein Warmwasserleck hinter einer Wand oder durch die charakteristische Wärmewolke austretenden Gases – bieten diese Kameras eine nicht-invasive, hochpräzise und schnelle Erkennungsmethode für verborgene Lecks.
Die Meinung von The Economist: In der Öl- und Gasindustrie werden Kameras mit optischer Gasbildgebung (OGI) unverzichtbar. Unternehmen wie FLIR sind führend mit Lösungen, die Hunderte von unsichtbaren Gasen sichtbar machen und es Inspektoren ermöglichen, Lecks sicher und effizient zu identifizieren, oft ohne kritische Systeme abschalten zu müssen. Dies ist besonders wichtig für Methan, ein starkes Treibhausgas; durch frühzeitige Erkennung können vermeidbare Emissionen um bis zu 70 % reduziert werden.
Der Einsatz geht über die Öl- und Gasindustrie hinaus. Wasserversorger setzen zunehmend Drohnen mit Wärmebildkameras ein, um große Netze schnell zu überwachen, was zu einer gemeldeten Reduzierung der Wasserverschwendung um bis zu 60 % führt. Bei dieser Verlagerung von reaktiven Reparaturen hin zu proaktiver, vorausschauender Wartung geht es nicht nur um Kosteneinsparungen, sondern auch um den Schutz von Menschenleben, die Umwelt und die Gewährleistung wirtschaftlicher Kontinuität.
Natürlich gibt es weiterhin Herausforderungen. Umweltbedingungen, die Notwendigkeit einer fachkundigen Auswertung und die anfänglichen Ausrüstungskosten sind Faktoren, die es zu berücksichtigen gilt. Die Zukunft sieht jedoch vielversprechend aus, da die Integration von KI und maschinellem Lernen automatisierte Analysen, sofortige Erkenntnisse und sogar vorausschauende Fehlererkennung verspricht. Stellen Sie sich Deep-Learning-Modelle vor, die Daten von mehreren Sensoren zusammenführen, um eine Genauigkeit von über 90 % zu erreichen und Fehlalarme drastisch zu reduzieren.
Für Unternehmen, die kritische Infrastrukturen verwalten, ist die Botschaft klar: Investieren Sie in leistungsstarke Wärmebildtechnik, legen Sie Wert auf umfassende Schulungen und integrieren Sie diese fortschrittlichen Tools in ein ganzheitliches Integritätsmanagementsystem. Nutzen Sie Drohnentechnologie und KI, um von isolierten Inspektionen zu einer kontinuierlichen, intelligenten Überwachung überzugehen. Dies ist nicht nur eine operative Verbesserung, sondern eine strategische Notwendigkeit für eine widerstandsfähigere, nachhaltigere und profitablere Zukunft.
Blogbeitrag vom 13. Juni 2025:
Die alles sehende, unsichtbare Hand
von Kevin Lancashire (Link zum Original-Text auf Englisch)

Die Zukunft, wie wir sie uns vorstellen: Wie sehende Maschinen unsere Welt still und leise verändern
Das große Ganze: In den letzten zehn Jahren hat eine stille, aber tiefgreifende industrielle Revolution stattgefunden – nicht in riesigen Fabriken, sondern in unseren Autos, unseren Häusern und unseren Taschen. Computer-Vision, einst eine akademische Nische, ist zum Motor einer neuen Klasse von „sehenden Werkzeugen” geworden. Die ungeschickten, halbautomatischen Helfer von 2015 haben sich zu intelligenten, wahrnehmungsfähigen Partnern entwickelt. Dies war keine einfache Geschichte von besseren Kameras oder schnelleren Chips, sondern das Ergebnis eines Paradigmenwechsels in der künstlichen Intelligenz, der Maschinen das Sehen, Interpretieren und Handeln beigebracht hat. Der Markt, der von geschätzten 23 Milliarden US-Dollar im Jahr 2025 auf über 63 Milliarden US-Dollar im Jahr 2030 wachsen soll, verlagert sich vom Verkauf neuartiger Gadgets hin zur Bereitstellung unverzichtbarer, bildverarbeitungsgestützter Dienste. In den nächsten fünf Jahren wird diese Technologie so grundlegend wie das Internet werden und sich unsichtbar in unser tägliches Leben einfügen.
Der Weg bis 2030: Eine Fünfjahresprognose
Die in den letzten zehn Jahren geleistete Vorarbeit – von vom kruden Verarbeiten früher neuronaler Netze bis zum differenzierten Verständnis heutiger Modelle – wird bis zum Ende des Jahrzehnts zu greifbaren, transformativen Ergebnissen führen. Der Fokus verlagert sich von einzelnen Aufgaben (z. B. „dieses Hindernis umgehen“) hin zu einem ganzheitlichen Verständnis der Umgebung („Was ist der Kontext dieses Raums und die Absicht seiner Bewohner?“). Dieser Sprung wird unsere Interaktion mit der physischen Welt in vier Schlüsselbereichen neu definieren.
1. Einfacheres Leben: Der Aufstieg des häuslichen Co-Piloten Bis 2030 wird das Konzept des „Smart Home“ antiquiert erscheinen. Wir treten in die Ära der aufmerksamen Umgebung ein. Vergessen Sie die heutigen Staubsaugerroboter; ihre Nachkommen werden Haushaltsroboter sein, die nicht nur reinigen, sondern auch aufräumen und organisieren können. Ausgestattet mit fortschrittlicher Bildverarbeitung und generativer KI werden diese Maschinen den Unterschied zwischen einem falsch abgelegten Buch und einem Stück Müll erkennen und Gegenstände an ihren vorgesehenen Platz zurückbringen. Dies geht über das Reinigen hinaus. Rechnen Sie damit, dass Ihre Küche mit intelligenten Assistenten ausgestattet sein wird, die Ihr Kochen visuell überwachen, Ihnen in Echtzeit Anweisungen zur Technik geben oder Sie warnen, bevor Sie die Zwiebeln anbrennen lassen. Hier geht es nicht um Neuheiten, sondern darum, das wertvollste Gut systematisch zurückzugewinnen: Zeit.
2. Mehr Sicherheit im Leben: Von reaktiven Warnungen zu vorausschauenden Schutzmaßnahmen Sicherheitsanwendungen werden eine entscheidende Entwicklung von der Reaktion zur Prävention durchlaufen.
• Im Auto: Die Sicherheit im Straßenverkehr wird über die Kollisionsvermeidung in letzter Sekunde hinausgehen. Bildverarbeitungssysteme, kombiniert mit Radar und Vehicle-to-Everything-Kommunikation (V2X), werden eine vorausschauende Sicherheitsblase um das Auto herum schaffen. Das System wird nicht nur einen Fußgänger sehen, der auf die Straße tritt, sondern es wird das Verhalten aller umgebenden Akteure – Fahrzeuge, Radfahrer und Fußgänger – modelliert haben, um ein solches Ereignis Sekunden vor seinem Eintreten zu antizipieren und die Geschwindigkeit oder Position subtil anzupassen, um sicherzustellen, dass die Gefahr nie eintritt. Dies ist der Weg, um die mehr als 90 % der durch menschliches Versagen verursachten Unfälle drastisch zu reduzieren.
• Zu Hause: Sicherheitssysteme werden sich zu Wellness-Monitoren entwickeln. Anstatt Sie lediglich auf eine offene Tür aufmerksam zu machen, lernen Bildverarbeitungssysteme die Umgebungsmuster Ihres Zuhauses kennen. Sie sind in der Lage, Anomalien passiv zu erkennen – eine Veränderung im Gangbild eines älteren Elternteils, eine ungewöhnlich lange Phase der Inaktivität oder das Vorhandensein eines unbekannten Fahrzeugs – und geben eine kontextbezogene, differenzierte Warnung aus. So entsteht ein Sicherheitsnetz, das sowohl leistungsfähiger als auch weniger aufdringlich ist.
3. Ein Leben mit weniger Fehlern: Der erweiterte Mensch Die grössten Reibungsverluste be vielen alltäglichen Aufgaben werden durch menschliche Fehler verursacht. Bis 2030 wird Computervision als universelle Fehlerkorrektur-Ebene fungieren, die über Augmented Reality (AR) bereitgestellt wird. Stellen Sie sich vor, Sie bauen ein Möbelstück aus einem Flachpaket zusammen. Eine AR-Brille, die mit Computer Vision ausgestattet ist, blendet digitale Anweisungen direkt auf die Komponenten in Ihrer realen Ansicht ein, hebt die richtige Schraube hervor und animiert den nächsten Schritt. Dieser „digitale Zwilling” für alltägliche Aufgaben wird sich auf DIY-Reparaturen, komplexe Kochrezepte und sogar auf die persönliche Fitness ausweiten, wo eine AR-Überlagerung Ihre Haltung in Echtzeit korrigieren kann. Das Ergebnis ist eine deutliche Reduzierung von Fehlern, Frustration und verschwendeter Mühe.
4. Mehr Lebensfreude: Nahtlose, personalisierte Realitäten Mit zunehmender Integration der Technologie wird sie in den Hintergrund treten und unsere Erfahrungen auf subtile Weise verbessern. Der Einzelhandel wird durch virtuelle Anprobe-Technologien transformiert werden, die von der Verwendung eines Spiegels nicht zu unterscheiden sind. Die Unterhaltung wird die Grenzen des Bildschirms sprengen, da AR-Anwendungen immersive, interaktive Erlebnisse schaffen, die sich über unser Wohnzimmer legen. Öffentliche Räume werden intuitiver werden, da Navigation und Informationen nahtlos in unserem Blickfeld erscheinen. Das Ziel dieses „Ambient Computing“ ist es, technologische Reibungsverluste zu beseitigen und eine natürlichere und angenehmere Interaktion mit der digitalen und der physischen Welt zu ermöglichen.
|
Aktuelle Herausforderungen |
Zukunftsaussichten |
Ethische Überlegungen |
|
• Robustheit: Leistungsabfall bei schlechtem Wetter, schlechter Beleuchtung oder verschmutzten Sensoren, |
• Sensorfusion: Enge Integration von |
• Überwachung: Potenzial für Missbrauch von |
|
• Randfälle: Ausfall bei seltenen Situationen, die in den Trainingsdaten nicht vorkommen. |
• Generative KI: Verwendung von KI zur Erstellung |
• Datensicherheit: Schutz sensibler visueller |
|
• Datenverzerrung: Modelle können Verzerrungen aus ihren Trainingsdaten übernehmen und verstärken. |
• Edge-KI: Mehr Verarbeitung auf dem Gerät für schnellere Reaktionen, besseren Datenschutz und Offline-Funktionalität. |
• Verantwortlichkeit: Feststellung der Haftung, wenn |
|
• Datenschutz: Sichere Verwaltung der riesigen Mengen an visuellen Daten, die von diesen Geräten erfasst werden. |
• Natürliche Interaktion: Kombination von Bildverarbeitung |
• Übermäßige Abhängigkeit: Risiko des Verlusts menschlicher Fähigkeiten |
Obwohl enorme Fortschritte erzielt wurden, ist der Weg noch lange nicht zu Ende. Die heutigen Systeme stoßen immer noch an Grenzen, und ihre zunehmende Komplexität wirft wichtige ethische Fragen auf und weist auf spannende neue Richtungen in der KI-Entwicklung hin.
Der Investitionsausblick: Von der Neuheit zur Notwendigkeit
Die wirtschaftlichen Auswirkungen dieses Wandels sind erheblich. Die erste Wachstumswelle wurde durch den Verkauf von Hardware angetrieben. Die nächste, weitaus größere Welle wird auf „Intelligence-as-a-Service“ basieren. Unternehmen werden nicht nur ein Gerät verkaufen, sondern ein laufendes Abonnement für ein sich ständig verbesserndes KI-Modell, das dessen Fähigkeiten erweitert.
Risikokapitalgeber verlagern ihren Fokus bereits von Hardware auf KI-native Lösungen, die in bestehende Ökosysteme eingebettet werden können. Es werden neue Marktführer entstehen, die das komplexe Zusammenspiel von Edge-Computing (Verarbeitung auf dem Gerät für Geschwindigkeit und Datenschutz) und Cloud-Computing (Zugriff auf umfangreiche Modelle für tiefere Analysen) beherrschen. Die erfolgreichsten Unternehmen werden diejenigen sein, die eine vertrauensvolle Beziehung zu den Verbrauchern aufbauen und die kritischen Herausforderungen des Datenschutzes und der Datensicherheit meistern.
Bis 2030 wird es nicht mehr darum gehen, ob ein Gerät über eine Kamera verfügt, sondern wie intelligent es sehen kann. Für Investoren, Unternehmen und Verbraucher gleichermaßen wird es entscheidend sein, über die Hardware hinauszuschauen und den tiefgreifenden Wert zu erkennen, der durch die Intelligenz hinter der Linse geschaffen wird.
Blogbeitrag vom 7. Juni 2025:
Die visuelle Revolution der KI: Drei Szenarien für den wirtschaftlichen und gesellschaftlichen Wandel
von Kevin Lancashire Link zum Original auf Englisch

Als jemand, der sich intensiv mit der Schnittstelle zwischen Technologie, Kreativität und Governance beschäftigt – von der Gestaltung von Klanglandschaften mit Synthesizern bis hin zur Navigation in der digitalen Kommunikation – beobachte ich mit großem Interesse die tiefgreifenden wirtschaftlichen und gesellschaftlichen Veränderungen, die durch fortschrittliche KI vorangetrieben werden. Ein besonders spannendes Gebiet ist die multimodale KI, wie sie beispielsweise durch die Echtzeit-Video-Funktionen (Computer Vision) von Gemini Live veranschaulicht wird. Dabei handelt es sich nicht nur um eine technologische Verbesserung, sondern um eine grundlegende Neugestaltung der Art und Weise, wie wir mit Informationen und der Welt interagieren.
Die Fähigkeit der KI, Live-Bilddaten zu sehen, zu verstehen und daraus Schlussfolgerungen zu ziehen, Werte auf eine beispiellose Weise erschließen und die Marktdynamik neu gestalten. Hier sind drei Szenarien, die ihr transformatives Potenzial und ihre realen wirtschaftlichen Auswirkungen veranschaulichen:
-
Die hyper-personalisierte Produktivitätsmaschine: Stellen Sie sich eine Zukunft vor, in der Ihr Smartphone, ausgestattet mit Gemini Live, zu einem allgegenwärtigen, proaktiven Assistenten wird. Richten Sie Ihre Kamera auf eine komplexe Aufgabe – beispielsweise ein neues Gartenprojekt oder eine Reparatur im Haus – und erhalten Sie sofort visuelle Anweisungen. Diese Art der kontextbezogenen Echtzeit-Unterstützung wird die individuelle Effizienz erheblich steigern, kognitive Belastungen reduzieren und Zeit für wertvollere Tätigkeiten freisetzen, was eine neue Welle der persönlichen wirtschaftlichen Otimierung auslösen wird.
-
Der erweiterte öffentliche und kommerzielle Bereich: Stellen Sie sich städtische Umgebungen und Einzelhandelsflächen vor, die durch allgegenwärtige Computer Vision verändert werden. Während Sie durch eine Stadt navigieren, könnte Ihr Gerät Echtzeit-Historien zu Gebäuden einblenden oder Sie anhand Ihrer visuellen Hinweise und Präferenzen zu bestimmten Produkten in einem Geschäft führen. Diese Hyper-Kontextualisierung wird das Verbrauchererlebnis neu definieren, die Ressourcenzuweisung in Smart Cities optimieren und neue Wege für den Handel eröffnen, wenn auch unter der Voraussetzung, dass robuste Rahmenbedingungen für den Datenschutz und die ethische Überwachung geschaffen werden.
-
Der KI-beschleunigte kreative und professionelle Nexus: Für Fachleute und Kreative bedeutet dies einen Paradigmenwechsel. Stellen Sie sich eine KI vor, die ein Musikvideo visuell analysieren und ergänzende Klangtexturen für Ihren nächsten Track vorschlagen kann, oder eine, die digitale Plattformen überprüft, Designtrends identifiziert und die Content-Strategie auf der Grundlage der visuellen Interaktion optimiert. Diese tiefgreifende, visuell orientierte Zusammenarbeit wird Innovationen beschleunigen, Forschung und Entwicklung rationalisieren und die Wettbewerbslandschaft in allen Branchen neu definieren, was erhebliche gesellschaftliche Investitionen in die Weiterbildung und Umschulung erfordert, um ihr volles Potenzial auszuschöpfen.
Diese Szenarien unterstreichen, dass die Computer Vision von Gemini Live mehr als nur eine Funktion ist – sie ist ein wirtschaftlicher Katalysator. Die Möglichkeiten für Effizienz, Innovation und personalisierte Dienstleistungen sind zwar immens, doch die Notwendigkeit einer ethischen Governance, Datensicherheit und eines gerechten Zugangs bleibt von größter Bedeutung. Der wahre Maßstab für diese Revolution wird unsere Fähigkeit sein, verantwortungsbewusst mit ihren Komplexitäten umzugehen und einen breiten gesellschaftlichen Nutzen sicherzustellen.
Was sind Ihre Erkenntnisse zu den wirtschaftlichen Auswirkungen der Echtzeit-Computer Vision?
Blogbeitrag vom 30. Mai 2025:
Turbo für Ärzte: Wie KI in der medizinischen Bildgebung zu schnelleren und genaueren Diagnosen führt.
von Kevin Lancashire Link zum Original auf Englisch

Das Unsichtbare sehen: Wie KI Ärzten Superkräfte verleiht und Ihre Gesundheit revolutioniert
Das Warten auf medizinische Testergebnisse kann eine Zeit großer Unsicherheit sein. Für medizinisches Fachpersonal besteht die Herausforderung darin, komplexe Scans akribisch zu untersuchen und nach winzigen, fast unsichtbaren Anzeichen einer Erkrankung Ausschau zu halten. Täglich wird eine immense Menge an medizinischen Bildern wie Röntgenaufnahmen, MRT- und CT-Scans erstellt. Dieser „massive Datenstrom“ setzt Radiologen und andere Gesundheitsdienstleister unter erheblichen Druck. Die Nachfrage nach diagnostischen Dienstleistungen wächst und übersteigt oft „das Angebot an medizinischem Fachpersonal“, sodass die derzeitigen Prozesse kaum noch Schritt halten können. Diese „Datenflut“ ist ein Hauptgrund für die Einführung neuer Technologien. Die schiere Menge an visuellen Informationen, die durch fortschrittliche Bildgebungstechniken wie Computertomographie (CT), Positronen-Emissions-Tomographie (PET) und Magnetresonanztomographie (MRT) erzeugt wird, kann für die menschliche Interpretation allein überwältigend sein. Glücklicherweise gibt es einen neuen leistungsstarken Verbündeten, der bei der Bewältigung dieser Herausforderungen helfen kann: Künstliche Intelligenz (KI). KI-Systeme sind aufgrund ihrer Fähigkeit, „große Mengen an Bilddaten in Sekundenschnelle zu analysieren“ und „riesige Datenmengen“ zu verarbeiten, in einer einzigartigen Position, um diese Herausforderungen zu bewältigen. Damit sind sie nicht nur ein neuartiges Werkzeug, sondern eine notwendige Weiterentwicklung im Gesundheitswesen.
Der Überblick: Was ist AI in der Medizinischen Bildgebung
Im Kern umfasst künstliche Intelligenz (KI) in der medizinischen Bildgebung den Einsatz hochentwickelter Computerprogramme, oft als Algorithmen bezeichnet, zur Analyse medizinischer Scans wie Röntgenbilder, Computertomographie (CT)-Scans und Magnetresonanztomographie (MRT)-Scans. Diese KI-Systeme sind so konzipiert, dass sie „die menschliche Wahrnehmung nachahmen“ oder „menschliches Denken imitieren“, wenn es darum geht, diese medizinischen Daten zu verarbeiten und zu interpretieren.
Stellen Sie sich das wie einen hochqualifizierten medizinischen Assistenten mit fast übermenschlicher Sehkraft vor. Dieser Assistent hat Millionen von Scans „studiert“ und gelernt, subtile Muster und winzige Details zu erkennen, die für das menschliche Auge möglicherweise schwer zu erkennen sind, insbesondere nach einem langen Arbeitstag, an dem zahlreiche Bilder gesichtet wurden. Diese Fähigkeit beruht auf der Stärke der KI in der Mustererkennung. Maschinelles Lernen und insbesondere sein Teilgebiet Deep Learning, das häufig konvolutionelle neuronale Netze nutzt, ermöglicht es diesen Systemen, komplexe „Muster und Anomalien“ aus riesigen Bilddatensätzen zu lernen. Bei der medizinischen Diagnose anhand von Bildern geht es im Wesentlichen darum, visuelle Muster zu erkennen – ein Tumor kann eine bestimmte visuelle Signatur haben, eine Fraktur eine andere. KI ist hervorragend geeignet für diese umfangreiche, detaillierte Mustererkennung und identifiziert „subtile Muster“ oder solche, „die für das menschliche Auge möglicherweise nicht offensichtlich sind“.
Es ist wichtig zu verstehen, dass das Ziel nicht darin besteht, qualifizierte medizinische Fachkräfte zu ersetzen. Stattdessen soll KI sie unterstützen und als leistungsstarkes Werkzeug zur Verbesserung ihrer Fähigkeiten dienen. Durch den Einsatz von Algorithmen für maschinelles Lernen können diese KI-Systeme medizinische Bilder mit bemerkenswerter Geschwindigkeit und Präzision analysieren, wodurch ihre Arbeit überschaubarer und ihre Diagnoseergebnisse zuverlässiger werden. Die „Trainingsmethoden“ für diesen KI-Assistenten, maschinelles Lernen und Deep Learning, ermöglichen es ihm, seine Analysefähigkeiten kontinuierlich zu verbessern, wenn er mit mehr Daten konfrontiert wird. Diese Kernkompetenz in der Mustererkennung ergänzt das unschätzbare Fachwissen menschlicher Ärzte, die einen breiteren klinischen Kontext, kritisches Denken und einfühlsame Patientenversorgung in den Diagnoseprozess einbringen.

Drei Wege, wie KI das Gesundheitswesen zum Besseren revolutioniert
Die Auswirkungen von KI auf die medizinische Bildgebung sind vielfältig und versprechen sowohl für Patienten als auch für das Gesundheitssystem greifbare Vorteile. Diese Technologie wird Diagnoseprozesse verbessern, Behandlungen personalisieren und medizinisches Fachpersonal auf beispiellose Weise unterstützen.
Positiver Aspekt 1: Krankheiten früher und genauer erkennen – Ein schärferer Blick auf Ihre Gesundheit
Einer der wichtigsten Vorteile von KI in der medizinischen Bildgebung ist ihr Potenzial, Krankheiten bereits im Frühstadium zu erkennen, oft mit grösserer Genauigkeit. KI-Algorithmen können winzige Anomalien in Scans identifizieren, die vom menschlichen Auge übersehen werden könnten, insbesondere in den Anfangsphasen von Erkrankungen wie Krebs oder Herzerkrankungen. Beispielsweise sind KI-gestützte Tools vielversprechend bei der Identifizierung kleiner Tumore, die sonst möglicherweise unbemerkt bleiben würden, bei der Erkennung früher Anzeichen von Lungenerkrankungen, Knochenbrüchen und verschiedenen Herzerkrankungen anhand von Röntgenaufnahmen oder bei der Lokalisierung von Lungenknoten in Thoraxröntgenaufnahmen und der Segmentierung von Hirntumoren in MRT-Scans mit bemerkenswerter Präzision. Untersuchungen haben gezeigt, dass Radiologen, die KI-Unterstützung zur Erkennung von Erkrankungen wie Lungenembolien in CT-Scans einsetzen, deutlich bessere Ergebnisse erzielen als diejenigen ohne solche Hilfe.
Diese verbesserte Diagnosegenauigkeit führt zu einer früheren Erkennung, was oft entscheidend für die Verbesserung der Patientenergebnisse und Überlebensraten ist. Wenn Krankheiten frühzeitig erkannt werden, sind die Behandlungsmöglichkeiten in der Regel zahlreicher und wirksamer. Darüber hinaus kann KI zu einer verbesserten Diagnosesicherheit und einer Verringerung von Fehlalarmen beitragen, was bedeutet, dass weniger Patienten unnötige Folgeuntersuchungen über sich ergehen lassen müssen und damit verbundene Ängste erleben.
Diese Fähigkeit bedeutet einen grundlegenden „proaktiven Wandel“ im Gesundheitswesen. Anstatt in erster Linie auf Krankheiten zu reagieren, sobald Symptome auftreten und der Zustand bereits fortgeschritten ist, ermöglicht KI einen Übergang zu einem präventiven Gesundheitsmanagement. Die Fähigkeit zur „Früherkennung“ bedeutet, Gesundheitsprobleme zu identifizieren, bevor sie zu ernsthaften Problemen werden, sodass Maßnahmen ergriffen werden können, wenn sie oft weniger invasiv und erfolgreicher sind. Wie einige Experten sich vorstellen, könnte KI die Möglichkeit bieten, „das Risiko eines Patienten für eine Krankheit zu erkennen und Präventionsmassnahmen zu ergreifen, lange bevor er tatsächlich an der Krankheit erkrankt“. Dieser Wandel hat tiefgreifende Auswirkungen auf die öffentliche Gesundheit, da er das Potenzial hat, die Gesamtbelastung durch chronische Krankheiten zu verringern, die langfristigen Gesundheitsausgaben zu senken und die Lebensqualität vieler Menschen erheblich zu verbessern.
Positiver Aspekt 2: Wegbereiter für personalisierte Behandlungen – Medizin, die für Sie massgeschneidert wird
Der Beitrag der KI geht über das bloße Aufspüren von Problemen hinaus: Sie hilft Medizinern, diese Probleme im Kontext des einzelnen Patienten besser zu verstehen. KI-Systeme können Bildgebungsdaten in Verbindung mit anderen Patienteninformationen wie der Krankengeschichte und in Zukunft sogar genetischen Daten analysieren, um vorherzusagen, wie eine bestimmte Krankheit verlaufen könnte oder wie ein Patient wahrscheinlich auf verschiedene Behandlungen anspricht.
Diese Fähigkeit ist von zentraler Bedeutung für die Weiterentwicklung der „Präzisionsmedizin“ oder „personalisierten Medizin“, bei der Behandlungspläne sorgfältig auf den Einzelnen zugeschnitten werden, um die Wirksamkeit zu maximieren und gleichzeitig mögliche Nebenwirkungen zu minimieren. Beispielsweise können KI-Algorithmen die einzigartigen Merkmale des Tumors eines Patienten anhand von Scans untersuchen und auf der Grundlage von Mustern, die aus umfangreichen Datensätzen gelernt wurden, die vielversprechendsten Therapieoptionen vorschlagen.
Diese Entwicklung hin zu personalisierten Behandlungen wird durch die Rolle der KI als leistungsstarker Integrator verschiedener Daten vorangetrieben, der eine „ganzheitliche Sicht auf den Patienten“ ermöglicht. Die Technologie entwickelt sich von einem spezialisierten Bildanalysator zu einem System, das ‚multimodale‘ Informationen verarbeiten kann. Dies, indem es „eine Vielzahl von Patientendaten“ integriert, nicht nur Scans, um ein „hochauflösendes Bild eines Menschen“ zu erstellen. Durch die Kombination von Bildgebungsergebnissen mit Elementen wie genetischen Informationen oder umfassenden Krankengeschichten trägt KI dazu bei, ein vollständigeres Bild der einzigartigen biologischen und klinischen Beschaffenheit eines Menschen zu erstellen. Dieses ganzheitliche Verständnis ist die Grundlage für eine wirklich personalisierte Medizin und ebnet den Weg für hochgradig differenzierte, datengestützte Behandlungsentscheidungen, die weit über Einheitslösungen hinausgehen. Dies unterstreicht auch die wachsende Bedeutung der Dateninteroperabilität und sicherer, umfassender elektronischer Gesundheitsakten.
Positive Erkenntnis 3: Ärzte stärken und Patientenversorgung verbessern – mehr Zeit für das Wesentliche
KI ist in der Lage, die Effizienz im Gesundheitswesen erheblich zu steigern, indem sie viele der zeitaufwändigen und repetitiven Aufgaben im Zusammenhang mit der medizinischen Bildgebung übernimmt. Beispiele hierfür sind die Automatisierung von Aspekten der Bildanalyse, die Unterstützung bei der Erstellung vorläufiger oder strukturierter radiologischer Befunde, die Durchführung von Bildsegmentierung (Identifizierung und Umrandung bestimmter Strukturen) und Annotation sowie die Kennzeichnung dringender Fälle, die sofortige Aufmerksamkeit erfordern.
Durch die Automatisierung dieser „alltäglichen“ oder „zeitaufwändigen Aufgaben“ kann KI Radiologen und andere Kliniker von mühsamer Arbeit befreien, wodurch ihre erhebliche Arbeitsbelastung reduziert und das Risiko eines Burnouts gemindert wird. Dadurch haben Ärzte mehr Zeit und mentale Energie, um sich den komplexesten Fällen zu widmen, sich direkt mit den Patienten auseinanderzusetzen und zu kommunizieren und sich auf wichtige klinische Entscheidungen zu konzentrieren. Diese Verlagerung führt nicht nur zu effizienteren Abläufen im Gesundheitswesen, sondern verbessert auch die gesamte Patientenerfahrung.
Diese „menschenzentrierte Effizienz“ legt nahe, dass KI die Medizin nicht entmenschlicht, sondern vielmehr dazu beitragen kann, sie wieder menschlicher zu machen. Indem sie die eher mechanischen Aspekte der Arbeit übernimmt, schafft KI mehr Raum für die einzigartigen menschlichen Elemente der Gesundheitsversorgung: Empathie, differenzierte Problemlösung und zwischenmenschliche Kommunikation. Die Aussicht auf „weniger Stress, ein ausgeglicheneres Leben“ für Ärzte und mehr Zeit, um „Beziehungen zu Patienten und Kollegen zu pflegen“, ist ein entscheidender Faktor für eine bessere, mitfühlendere Versorgung. Dies verändert die Sichtweise auf den Einsatz von KI: Es geht nicht nur um Geschwindigkeit und Genauigkeit, sondern auch um die Optimierung des Gesundheitswesens, damit menschliche Fähigkeiten dort zum Einsatz kommen, wo sie am wertvollsten sind.
|
AI in der Medizinischen Bildgebung: Ein Schnappschuss der Schlüssel-Vorteile |
||
|
Vorteil-Kategorie |
Was es für den Patienten bedeutet |
Wie es dem Arzt hilft |
|
Frühere, genauere Diagnose |
Krankheiten früher erkennen, wenn sie noch besser bahandelbar sind: grösseres Vertrauen in die Diagnose. |
Verbesserte Fähigkeit leichte Krankheitssymptome zu finden; Reduziertes Risiko für Diagnosefehler. |
|
Personalisierte Behandlungspläne |
Behandlung die für den einzigartigen Körper und Zustand des Patienten angepasst sind. Dies verbessert die Effizienz und reduziert Nebenwirkungen. |
Besser Werkzeuge um die Antwort auf die Behandlung vorherzusagen. Fähigkeit, hoch individualisierte Behandlungsstrategien zu entwickeln. |
|
Befähigte medizinische Fachpersonen und effiziente Pflege |
Schnellere Resultat von Scans; Ärzte haben mehr Zeit, die Behandlung zu diskutieren. |
Geringere Arbeitsbelastung durch Routineaufgaben. Mehr Zeit für komplexe Fälle und direkten Patientenkontakt. Effizientere Prozesse. |
A snapshot of how AI is transforming medical imaging, highlighting key benefits for patients, such as more accurate and timely diagnoses, and for doctors, including enhanced detection capabilities and streamlined workflows.
Ein Blick in eine gesündere Zukunft – Was kommt als Nächstes?
Die bisherigen Fortschritte sind nur der Anfang der transformativen Entwicklung der KI in der medizinischen Bildgebung. Die Zukunft hält noch spannendere Möglichkeiten bereit. Experten erwarten den Aufstieg der „prädiktiven Medizin“, bei der KI anhand subtiler Hinweise in den Daten eines Patienten dessen Risiko, bestimmte Krankheiten zu entwickeln, möglicherweise Jahre im Voraus vorhersagen könnte. Stellen Sie sich vor, KI-Algorithmen könnten allein anhand elektronischer Gesundheitsakten das Risiko für Bauchspeicheldrüsenkrebs bewerten oder Brustkrebs lange vor seinem klinischen Auftreten vorhersagen.
Wir bewegen uns auch in Richtung einer „Echtzeit-KI-gestützten Diagnose“, bei der KI den Ärzten während des Scanvorgangs selbst sofortiges Feedback geben könnte, um sie bei der Durchführung von Verfahren zu unterstützen und schnellere Entscheidungsfindung zu unterstützen. Darüber hinaus verbessert KI die 3D-Bildgebungsfunktionen und bietet noch detailliertere und interaktivere Ansichten komplexer Erkrankungen. Diese 3D-Modelle, die manchmal in die virtuelle Realität projiziert werden, können für die präoperative Planung und vor allem für die Aufklärung der Patienten von unschätzbarem Wert sein, da sie den Betroffenen und ihren Familien helfen, ihre Erkrankungen besser zu verstehen.
Die übergeordnete Vision ist eine enge Zusammenarbeit zwischen KI und menschlichen Experten. Das ideale Szenario sieht eine „Partnerschaft zwischen einem erfahrenen Radiologen und einem transparenten und erklärbaren KI-System“ vor, bei der „sie gemeinsam besser sind als jeder für sich allein“. Diese „zukünftige Zusammenarbeit zwischen KI und Mensch“ zielt darauf ab, die analytischen Fähigkeiten der KI zu nutzen, um Ärzte in ihrer Arbeit noch besser zu machen.
Dieser technologische Fortschritt birgt auch ein „Demokratisierungspotenzial“. Wenn KI-Tools komplexe diagnostische Analysen automatisieren oder erheblich unterstützen können, könnten sie hochgradiges Fachwissen einem breiteren Publikum zugänglich machen und damit möglicherweise die Gesundheitsversorgung in unterversorgten Gebieten oder Regionen mit weniger Fachärzten verbessern. Während die Senkung der Screening-Kosten ein erwarteter Vorteil ist, besteht die weiterreichende Auswirkung darin, dass mehr Menschen Zugang zu fortschrittlicher Diagnostik erhalten. Dies könnte dazu beitragen, Lücken in der Gesundheitsversorgung zu schließen, obwohl die Verwirklichung dieses Potenzials davon abhängt, dass die digitale Kluft überwunden wird und sichergestellt wird, dass diese Tools weltweit zugänglich und erschwinglich sind.
Damit diese Fortschritte jedoch vollständig realisiert und angenommen werden können, sind Vertrauen und Transparenz von entscheidender Bedeutung. Um dieses Vertrauen aufzubauen, müssen „faire und repräsentative KI-Modelle entwickelt und Systeme geschaffen werden, die ihre Argumentation transparent erklären“. Sowohl Patienten als auch Ärzte müssen die von KI generierten Erkenntnisse verstehen und ihnen vertrauen können, insbesondere wenn es um kritische Gesundheitsentscheidungen geht. Die „Black-Box“-Natur einiger KI-Systeme ist ein bekanntes Problem, an dessen Lösung die Branche durch erklärbare KI (XAI) aktiv arbeitet. Eine robuste Validierung dieser Tools, die Einhaltung ethischer Richtlinien, die Gewährleistung strenger Datensicherheit zum Schutz sensibler Patientendaten und die Aufrechterhaltung einer offenen Kommunikation sind von entscheidender Bedeutung für eine breite Akzeptanz und um sicherzustellen, dass KI wirklich im besten Interesse der Patienten eingesetzt wird.
Quellen:
-
jmir.org Future Use of AI in Diagnostic Medicine: 2-Wave Cross-Sectional Survey Study
-
mgma.com Artificial intelligence in diagnosing medical conditions and impact on healthcare
-
webmobtech.com How Computer Vision is Revolutionizing Healthcare – WebMob Technolo…
-
lakezurichopenmri.com AI in Medical Imaging: Transforming the Future of Diagnostics
-
rsna.org Role Of AI In Medical Imaging | RSNA
-
stjude.org Technology tidalwave: How artificial intelligence is shaping the…
-
spectral-ai.com Artificial Intelligence in Medical Imaging | AI in Imaging – Spectral AI
Dieser Newsletter profitierte von einer umfassenden Zusammenarbeit mit Google Gemini, das den Recherche- und Erstellungsprozess unterstützte.
Blogbeitrag vom 27. Mai 2025:
Ist Ihre SEO-Strategie bereit für die KI-Übersicht von Google?
von Kevin Lancashire Link zum Original auf Englisch (plus Whitepaper)
Das Spiel ist nicht mehr das gleiche. Sich auf alte Keyword-Taktiken zu verlassen, reicht nicht mehr aus, um Sichtbarkeit zu sicher zu stellen. Der Traffic verlagert sich, und viele sehen einen Rückgang.
Warum sollten Sie meine Meinung lesen? Ich habe die vielen Informationen zu dem Thema in ein 5-stufiges strategisches Rahmenwerk destilliert, das Ihnen hilft, sich anzupassen und in diesem neuen Umfeld zu siegreich zu werden. Erfahren Sie, wie!
✅ Verstärken Sie E-E-A-T als Ihr neues Fundament.
✅ Wechseln Sie von Schlüsselwörtern zu umfassenden Themenclustern.
✅ Strukturieren Sie Inhalte so, dass sie von KI verstanden und zitiert werden können.
✅ Verstärken Sie die Autorität Ihrer Marke im gesamten Web.
✅ Messen Sie den Erfolg in einer Welt jenseits einfacher Klicks.
Dies ist Ihr Leitfaden, um Ihre digitale Präsenz zukunftssicher zu machen.
Der erste Schritt ist die Erstellung beeindruckender Inhalte. Wir sind hier, um Ihnen dabei zu helfen, es richtig zu machen.
Wir bieten Ihnen einen präzisen 5-Schritte-Plan zur Anpassung an. Er deckt die wesentlichen Veränderungen ab, die Sie in Bezug auf Inhalte, technische SEO und Markenautorität vornehmen müssen, um sichtbar und relevant zu bleiben. Bleiben Sie nicht in der Vergangenheit stehen. Sie finden hier das Whitepaper zum Download:
KI Suche: Strategien für Sichtbarkeit

Blogbeitrag vom 24. Mai 2025:
KI kann nun sehen. Die wirtschaftlichen Folgen sind tiefgreifend
von Kevin Lancashire (Link zum Originalbeitrag in Englisch)

Googles jüngste KI-Demonstrationen lassen einen strategischen Schwenk erkennen, bei dem die Fähigkeit, die visuelle Welt zu interpretieren, zur Hauptarena des wirtschaftlichen Wettbewerbs wird.
Die wichtigste Erkenntnis aus den jüngsten Ankündigungen von Google war nicht die Gesprächsfähigkeit seiner KI, sondern die Tatsache, dass seine KI jetzt sehen kann. Jahrelang war die Computervision ein eine Technologie für eintönige, repetetive Aufgaben, die Gesichter auf Fotos erkennen oder Defekte in einer Fertigungsstraße aufspüren konnte. Doch die jüngsten Fortschritte zeigen, dass sie sich von einem passiven Analysewerkzeug zu einem aktiven, interaktiven Sinn entwickelt hat.
Dieser Übergang ist die wichtigste Entwicklung im heutigen Technologiesektor. Sie ist wichtig, weil sie den größten und am wenigsten genutzten Datensatz der Welt erschließt: Echtzeit-Videos aus der realen Welt. Bei dem Wettbewerb um die führende KI-Plattform geht es nicht mehr um die Verarbeitung von Text, sondern um die kommerzielle Interpretation der Realität selbst.
Im Mittelpunkt dieses Wandels steht ein grundlegender technologischer Sprung. Die Computer Vision geht über die einfache Objekterkennung hinaus und ermöglicht ein umfassendes Verständnis der Szene. Es ist der Unterschied zwischen einer KI, die einen „Schraubenschlüssel“ und eine „Mutter“ identifiziert, und einer KI, die versteht, dass „der verstellbare Schraubenschlüssel gerade benutzt wird, um eine Sechskantmutter an einem undichten Rohr unter dem Waschbecken festzuziehen“.
Diese Technologie liegt Project Astra zugrunde, dem visuellen Echtzeit-Assistenten von Google. Durch die Verarbeitung eines kontinuierlichen Videostroms baut die KI ein Kurzzeitgedächtnis für das Gesehene auf, das es ihr ermöglicht, den Kontext zu verstehen, Objekte zu verfolgen und mit einem Nutzer über die gemeinsame physische Umgebung zu interagieren.
Die wirtschaftlichen Auswirkungen dieser Entwicklung sind tiefgreifend und lassen sich in zwei Schlüsselbereiche einteilen:
Erstens ist die Computer Vision die Brücke, die es der Software ermöglicht, in die physische Wirtschaft vorzudringen. Die Softwareindustrie hat sich in der Vergangenheit auf digitale Aufgaben beschränkt. Ein „KI-Agent“, der seine Umgebung sehen und verstehen kann, kann einen Techniker durch eine komplexe Reparatur führen, einen Käufer in einem weitläufigen Supermarkt zu einem bestimmten Produkt leiten oder überprüfen, ob eine Baustelle den Sicherheitsvorschriften entspricht. Damit erhält die Software die Kontrolle über Atome, nicht nur über Bits, und stellt Geschäftsmodelle in Frage, die sich auf spezielle visuelle Fachkenntnisse von Menschen stützen, von der Qualitätssicherung bis zur Verkaufsförderung im Einzelhandel.
Zweitens kann eine KI mit demselben tiefen Verständnis der visuellen Welt, das sie in die Lage versetzt, eine Szene zu interpretieren, auch eine solche erstellen. Dies ist der Motor hinter generativen Modellen wie Veo, das Videos aus Text erstellt. Dies ist mehr als nur eine Bedrohung für die Medien- und Werbeindustrie; es ist der Beginn einer generativen Bildwirtschaft. Die Fähigkeit, fotorealistische synthetische Daten zu erstellen, wird ein entscheidender Vorteil für das Training anderer KI, das Entwerfen und Testen von Produkten in Simulationen und die Erzeugung hyperpersonalisierter visueller Inhalte in einem bisher unvorstellbaren Umfang sein.
Letztlich bestätigen die Ankündigungen von Google, dass Computer Vision nicht länger eine Nischendisziplin innerhalb der KI ist. Sie ist der zentrale Pfeiler für die nächste Generation von Benutzeroberflächen und Wirtschaftsplattformen. Das immense Kapital, das Google, OpenAI und Meta in diesen Bereich stecken, dient nicht nur dazu, intelligentere Geräte zu bauen. Es ist eine strategische Wette darauf, dass das Unternehmen, das den Maschinen beibringt, unsere Welt am effektivsten zu sehen und zu verstehen, auch dasjenige sein wird, das die Kapital- und Arbeitsströme in dieser Welt lenkt.
Im Folgenden wurde die obige Analyse umgeschrieben, um sich speziell auf die Computer Vision als wichtigste technologische Triebkraft zu konzentrieren. Dabe wurde bei die Perspektive eines Journalisten der Financial Times eingenommen.
Die neue Vision: Wie sehende KI den Markt neu gestalten wird
Die neuesten Systeme von Google zeigen, dass sich die Computer Vision von einem passiven Werkzeug zu einem aktiven, interaktiven Sinn entwickelt hat. Dieser Wandel wird enorme neue wirtschaftliche Möglichkeiten eröffnen und etablierte Branchen auf den Kopf stellen.
Auf seiner jüngsten I/O-Konferenz stellte Google seine neue Strategie vor, deren Kernstück ein grundlegender technologischer Wandel ist: Beim Computersehen geht es nicht mehr nur um Erkennung. Die Fähigkeit einer künstlichen Intelligenz, die Welt nicht nur durch eine Kamera zu sehen, sondern sie auch in Echtzeit zu verstehen, sich an das Gesehene zu erinnern und sich darüber zu unterhalten, markiert einen entscheidenden Wendepunkt.
Dies ist wichtig, weil es die Computer Vision zur wichtigsten Brücke zwischen der physischen Welt der Atome und der digitalen Welt der Software macht. Jahrzehntelang wurde der Wert von Software durch die Notwendigkeit einer menschlichen Übersetzung eingeschränkt – ein Mensch, der einer Maschine erklärt, was in der realen Welt passiert. Googles Demonstrationen von Project Astra, einem multimodalen Echtzeitsystem, zielen darauf ab, diese Barriere niederzureißen. Dies hat tief greifende wirtschaftliche Folgen.
Die wichtigste Auswirkung ist die Kommerzialisierung eines neuen, unvorstellbar großen Datensatzes: die visuelle Live-Realität. Eine KI, die einen Videostrom kontinuierlich interpretieren kann, ist in der Lage, Daten über alles zu erfassen und zu strukturieren, vom Kundenverhalten in einem Einzelhandelsgeschäft bis hin zu ineffizienten Arbeitsabläufen in einer Fabrikhalle. Dies stellt eine neue Grenze für die Monetarisierung von Daten dar, die weit über Klicks und Suchanfragen hinausgeht und in die Struktur der täglichen wirtschaftlichen Aktivitäten eindringt.
Diese fortschrittliche Form des Computersehens droht, bestimmte Formen visueller Expertise von Menschen zu einem Massenprodukt zu machen. Die Kernfunktion eines Qualitätskontrolleurs, eines Einzelhandelskaufmanns, der eine Auslage arrangiert, oder sogar eines Radiologen, der einen ersten Scan durchführt, besteht darin, eine geschulte visuelle Analyse durchzuführen. Wenn eine KI in der Lage ist, mit diesem Maß an kontextuellem Verständnis zu sehen, verändert sie den Wert dieser menschlichen Arbeit grundlegend und schafft Möglichkeiten für massive Effizienzsteigerungen, aber auch für eine erhebliche Verdrängung.
Außerdem ist dieser Sprung in der visuellen Interpretation untrennbar mit der explosionsartigen Zunahme der visuellen Kreation verbunden. Die Technologie, die Veo, dem neuen Text-zu-Video-Modell von Google, zugrunde liegt, beruht auf demselben tiefen Verständnis der visuellen Semantik. Eine KI muss zunächst die Physik von Licht, Bewegung und Objektinteraktion verstehen, bevor sie ein realistisches Video davon erstellen kann.
Dies schafft eine neue „Generative Vision Economy“. Die Auswirkungen beschränken sich nicht auf die disruption von Hollywood-Produktionsstudios oder Werbeagenturen. Sie ermöglicht die Erstellung synthetischer visueller Daten, um andere KI in großem Maßstab zu trainieren, die Erzeugung hyperrealistischer Simulationen für Technik und Produktdesign und die Fähigkeit, auf Anfrage personalisiertes visuelles Marketing zu produzieren. Dies senkt die Kosten für die Erstellung visueller Inhalte auf nahezu Null und verlagert den Wert von der Produktion auf den kreativen Impuls hinter dem Prompt.
Im Grunde genommen ging es bei den Ankündigungen von Google nicht um eine Reihe neuer Produkte. Sie waren eine einheitliche Aussage, dass die Computer Vision zur zentralen Säule der nächsten Computerplattform gereift ist. Der Kampf um die technische Vorherrschaft findet nicht mehr nur in der Cloud oder auf dem Smartphone statt, sondern in der Fähigkeit, die Pixelflut der Kameras dieser Welt zu interpretieren und darauf zu reagieren. Für Investoren und Unternehmensstrategen lautet die Schlüsselfrage nicht mehr, ob sehende KI ihren Sektor umgestalten wird, sondern wie sie sich anpassen können, wenn ihre Software, ihre Kunden und ihre Wettbewerber schliesslich sehen können.
Blogbeitrag vom 17. Mai 2025:
Die Seele von „Swiss Made“ wird durch AI nicht ersetzt, sondern geschützt und perfektioniert
von Kevin Lancashire (Link zum Originalbeitrag in Englisch)

Seit Jahrhunderten steht die Schweizer Uhrmacherei für unvergleichliche Präzision, Handwerkskunst und Luxus. Doch wie kann diese tief in der Tradition verwurzelte Branche ihren Vorsprung und ihre Integrität auch im digitalen Zeitalter bewahren?
Computer Vision (CV), ein leistungsstarker Bereich innerhalb der KI, erweist sich als transformative Kraft.
Hier erfahren Sie, warum sie immer wichtiger und wertvoller wird:
-
Qualitätsverbesserung auf mikroskopischer Ebene: CV-Systeme erkennen winzige Defekte an Komponenten wie Zifferblättern, Zeigern und Uhrwerksteilen mit außergewöhnlicher Genauigkeit (Studien zeigen eine Genauigkeit von mehr als 98 %), die über die menschlichen Fähigkeiten hinausgeht. So wird sichergestellt, dass jeder Zeitmesser den strengen „Swiss Made“-Standards entspricht. Denken Sie an Messungen im Submikrometerbereich, die perfekte Passform und Funktion gewährleisten.
Beispiele: Unternehmen wie MVTec via der Petitpierre SA nutzen CV für die berührungslose Inspektion mikromechanischer Teile für KIF Parechoc, und die Systeme von EthonAI helfen Herstellern, durch frühzeitiges Erkennen von Fehlern den Ausschuss zu reduzieren.
-
Stärkung der Authentizität und Bekämpfung von Fälschungen: Da die Industrie jährlich geschätzte 2 Milliarden Dollar durch Fälschungen verliert, ist der Schutz der Markenintegrität von größter Bedeutung. CV bietet robuste Lösungen zur Bekämpfung von Fälschungen.
Beispiele: AlpVision verwendet mikroskopische Fingerabdrücke auf der Oberfläche, die mit einer Smartphone-App verifiziert werden können. Die ORIGYN Foundation erstellt einzigartige „biometrische Fingerabdrücke“ für Uhren, die mit Blockchain-gestützten NFTs verknüpft sind und ein unveränderliches digitales Echtheitszertifikat liefern, das für den wachsenden Gebrauchtmarkt (der bis 2025 voraussichtlich 29-32 Milliarden Dollar erreichen wird) von entscheidender Bedeutung ist.
Dabei geht es nicht darum, den Kunsthandwerker zu automatisieren, sondern sein unglaubliches Können durch unerschütterliche Präzision und nachprüfbare Herkunft zu ergänzen. CV ermöglicht jenes Maß an Qualitätskontrolle und Markenschutz, das auf einem anspruchsvollen globalen Markt immer wichtiger wird.
Der strategische Wert liegt auf der Hand: das Versprechen „Swiss Made“ aufrechtzuerhalten, sich von der Konkurrenz abzuheben und eine ikonische Branche zukunftssicher zu machen.
Was denken Sie darüber, wie traditionelle Luxusindustrien Spitzentechnologie am besten integrieren können? #SwissWatchmaking #ComputerVision #AI #Manufacturing #LuxuryGoods #QualityControl #Authenticity #Blockchain
Blogbeitrag vom 9. Mai 2025:
Low-Code-Plattformen demokratisieren den Bereich der Computer Vision
von Kevin Lancashire (Link zum Originalartikel in Englisch)

Die geheimnisvolle Kunst der Computer Vision, die es Maschinen ermöglicht, die Welt zu „sehen“ und zu interpretieren, war zu lange den spezialisierten KI-Teams vorenthalten. Die Kosten für den Einstieg, sowohl in Bezug auf die Gewinnung von Talenten als auch auf die langwierigen Entwicklungszyklen, stellten für viele Unternehmen, die das transformative Potenzial visueller Daten nutzen wollten, eine erhebliche Hürde dar. Es ist jedoch ein seismischer Wandel im Gange, der durch den Aufstieg von Low-Code/No-Code-Plattformen vorangetrieben wird, die den Schlüssel zum visuellen Königreich an ein viel breiteres Publikum weitergeben.
Die Implikationen sind tiefgreifend. Stellen Sie sich ein mittelständisches Fertigungsunternehmen im Schweizer Mittelland vor, das nun in der Lage ist, eine automatische Fehlererkennung an seiner Produktionslinie einzusetzen, ohne dass eine Phalanx von Datenwissenschaftlern benötigt wird. Stellen Sie sich ein Einzelhandelsunternehmen in Manhattan vor, das durch einfaches Ziehen und Ablegen vorgefertigter Analysemodule detaillierte Einblicke in das Kundenverhalten in seinen Geschäften erhält. Dies ist keine bloße Zukunftsmusik, sondern die greifbare Realität, die durch diese intuitiven Entwicklungsumgebungen geschaffen wird.
Diese Plattformen, die von aufstrebenden Unternehmen wie unserem hypothetischen „VisionFlow“ angeboten werden, bieten einen überzeugenden Mehrwert. Durch die Abstrahierung der komplizierten Komplexität von Modelltraining, -einsatz und -integration befähigen sie Fachexperten – also genau die Personen, die die geschäftlichen Herausforderungen am besten verstehen -, maßgeschneiderte Bildverarbeitungslösungen zu entwickeln und zu implementieren. Die traditionellen Engpässe durch langwierige Programmierarbeiten und den Mangel an Fachkräften werden systematisch abgebaut.
Die wirtschaftlichen Auswirkungen sind beträchtlich. Geringere Entwicklungskosten und kürzere Einführungszeiten bedeuten für Unternehmen, die sich auf dieses technologische Terrain wagen, eine schnellere Kapitalrendite. Darüber hinaus fördert die Möglichkeit für nichttechnisches Personal, direkt zur Entwicklung von KI-gestützten Bildverarbeitungsanwendungen beizutragen, eine Kultur der Innovation und Agilität, die es den Unternehmen ermöglicht, rascher auf die sich verändernden Marktanforderungen zu reagieren.
Natürlich ist der Aufstieg von Low-Code/No-Code in der Computer Vision mit Vorbehalten verbunden. Bedenken hinsichtlich der Robustheit und Skalierbarkeit von Lösungen, die auf diesen Plattformen aufgebaut sind, sowie das Potenzial eines „Black-Box“-Effekts, bei dem die zugrunde liegenden Mechanismen für den Benutzer undurchsichtig bleiben, sind berechtigte Einwände. Darüber hinaus kann sich der Grad der Anpassung, der in diesen Umgebungen erreicht werden kann, bei bestimmten hochspezialisierten Anwendungen als Einschränkung erweisen.
Dennoch ist der übergreifende Trend unbestreitbar. Low-Code-/No-Code-Plattformen demokratisieren den Zugang zu einer leistungsstarken Technologie und lösen eine Welle von Innovationen in verschiedenen Sektoren aus. Von der Verbesserung der betrieblichen Effizienz bis hin zur Schaffung neuartiger Kundenerlebnisse – die Fähigkeit, die Kraft des Sehens zu nutzen, wird in den kommenden Jahren zu einem entscheidenden Wettbewerbsvorteil werden. Die verpixelte Zukunft, so scheint es, wird zunehmend für alle zugänglich.
Die zunehmende Verbreitung von Low-Code/No-Code-Plattformen demokratisiert die Computer Vision und macht ihre leistungsstarken Erkenntnisse für alle Unternehmen zugänglich, unabhängig von ihren technischen Kenntnissen. Dies beschleunigt die Innovation, senkt die Kosten und ermöglicht es Fachleuten, maßgeschneiderte visuelle Lösungen zu entwickeln, die branchenübergreifend neue Anwendungen erschließen. Sind Sie bereit zu sehen, was möglich ist? Kontaktieren Sie Day 1 Technologies. Schnell – erfahren – global.
Kim Vemula – CSO und Mitbegründer (2017)
Kevin Lancashire – CDO Europa
Beispiele:
Clarifai: Eine dedizierte KI-Plattform, die auf Computer Vision, Verarbeitung natürlicher Sprache und Audioerkennung spezialisiert ist. Sie bietet eine umfassende Suite für den gesamten KI-Lebenszyklus, einschließlich Datenaufbereitung, Modellentwicklung und Bereitstellung, mit einem starken Fokus auf No-Code-Workflows für visuelle Daten.
Lobe AI (Microsoft): Entwickelt, um Benutzern ohne Programmierkenntnisse die Möglichkeit zu geben, Computer-Vision-Modelle zu erstellen und einzusetzen. Es bietet eine benutzerfreundliche visuelle Schnittstelle für das Training von Modellen zur Bildklassifizierung und Objekterkennung mit nahtloser Integration in das Microsoft-Ökosystem.
Google Teachable Machine: Ein webbasiertes Tool, das maschinelles Lernen für jedermann zugänglich machen soll. Es ermöglicht den Nutzern die Erstellung von Computer-Vision-Modellen für die Bild-, Ton- und Posenerkennung über eine intuitive, programmierfreie Schnittstelle. Die Modelle lassen sich leicht exportieren und in verschiedenen Anwendungen verwenden.
Nanonets: Eine KI-Plattform ohne Code, die speziell für die Extraktion von Informationen aus visuellen Dokumenten und die Durchführung von Computer-Vision-Aufgaben entwickelt wurde. Sie zeichnet sich in Bereichen wie OCR, Objekterkennung in Dokumenten und Bildklassifizierung für die Dokumentenverarbeitung aus.
RunwayML: Richtet sich an Kreative und Macher und bietet eine No-Code-Plattform zum Trainieren und Bereitstellen von KI-Modellen, einschließlich solcher für Bildsynthese, Stilübertragung und Objekterkennung. Die intuitive Benutzeroberfläche macht maschinelle Lerntechniken für Künstler und Designer zugänglich.
MonkeyLearn: MonkeyLearn ist zwar stark in der Textanalyse, bietet aber auch No-Code-Tools für die Bildklassifizierung, mit denen Benutzer visuelle Inhalte nach bestimmten Kategorien und Erkenntnissen analysieren können.
AWS Panorama: AWS Panorama ist zwar auf die Bereitstellung von Computer Vision auf Edge-Geräten ausgerichtet, bietet aber auch eine No-Code-Schnittstelle für den Anschluss von IP-Kameras, die Auswahl vorgefertigter Modelle und die Erstellung von Bildverarbeitungsanwendungen für Industrie- und Unternehmensanwendungen.
IBM Maximo Visual Inspection: Als Teil der IBM Maximo-Suite bietet diese Plattform No-Code-Tools zum Trainieren und Bereitstellen von Computer-Vision-Modellen für die industrielle Inspektion, Qualitätskontrolle und Fehlererkennung.
Dataiku: Dataiku ist eine umfassendere Data-Science-Plattform und bietet visuelle Tools und vorgefertigte Rezepte, die es Benutzern mit begrenzten Programmierkenntnissen ermöglichen, Computer-Vision-Modelle in größeren Data-Science-Workflows zu erstellen und einzusetzen.
OpenCV AI Kit (OAK) Ecosystem (mit Plattformen wie Roboflow): Während OAK selbst Hardware erfordert, bieten Plattformen wie Roboflow eine programmierfreie Schnittstelle für Datenkommentierung, Vorverarbeitung und Modelltraining speziell für die Verwendung mit OAK-Geräten, was die Entwicklung eingebetteter Bildverarbeitungslösungen vereinfacht.
Blogbeitrag vom 2. Mai 2025:
Schärfere Augen, sicherere Zugänge: Konkrete Ausblicke für Computer-Vision in der Kundenidentifikation «KYC» (Know Your Customer)
Von Kevin Lancashire

Wir wissen, dass Computer Vision (CV) bereits der Antrieb hinter der Überprüfung von Identitätsdokumenten und dem Abgleich von Gesichtern in digitalen Know Your Customer (KYC) Prozessen ist. Mit der rasanten Entwicklung der CV-Technologie werden die Möglichkeiten der Identitätsüberprüfung jedoch weitaus granularer und ausgefeilter werden.
Die zentrale Frage ist nicht nur, wie die Zukunft aussehen wird, sondern vor allem: Was genau wird fortschrittliches CV im Bereich KYC ermöglichen? Und vor allem: Und was? Welche greifbaren Auswirkungen werden diese spezifischen Fähigkeiten haben?
Hier sind drei konkrete Beispiele:
1. Fähigkeit: Mikro-Muster- und Materialanalyse
Was wird möglich sein? Künftige CV-systeme werden nicht nur Text lesen und das grundlegende Layout von Ausweisen überprüfen. Sie werden mikroskopische Details des Dokumentenmaterials, Tinteneigenschaften, Drucktechniken und eingebettete Sicherheitsmerkmale wie Hologramme oder Mikrotext auf einer für das menschliche Auge unsichtbaren Ebene analysieren. Durch den Vergleich dieser komplizierten visuellen Muster mit umfangreichen Datenbanken bekannter echter Dokumente und Materialien können sie die subtilsten Anzeichen von Fälschungen oder Manipulationen erkennen – sogar bei Ausweisen und Dokumenten, die von erfahrenen Fälschern hergestellt wurden.
Was bedeutet das? Es bedeutet eine erhebliche Erhöhung der Sicherheit gegen raffinierten Identitätsbetrug. Unternehmen, die sich bei der Identifikation der Klienten darauf verlassen, werden das Risiko, dass Personen mit gefälschten Dokumenten von hoher Qualität Zugang gewährt bekommen, drastisch reduzieren, nachgelagerte Finanzkriminalität verhindern und sich vor behördlichen Strafen und Rufschädigung in Verbindung mit der Förderung illegaler Aktivitäten schützen. Für geschickte Betrüger wird es sehr viel schwieriger, die Zugangssicherung zu überwinden.
2. Fähigkeit: Fortgeschrittene Lebendigkeits- & Täuschungs-Erkennung
Was wird möglich sein? Bei der derzeitigen Überprüfung der Echtheit müssen Sie vielleicht blinzeln oder den Kopf drehen. Fortgeschrittene Computer-Vision wird weitaus subtilere Hinweise aus einer Live-Videoübertragung analysieren. Dazu gehören die Erkennung von Mikroausdrücken, die Analyse des Blutflusses unter der Haut (zur Erkennung von Masken oder Fotos), die Erkennung von Diskrepanzen bei Beleuchtung und Schatten, die einen Bildschirm oder eine Projektion verraten, und die Erkennung von Anomalien, die für synthetisch erzeugte Medien wie Deepfakes charakteristisch sind.
Dies bietet einen robusten Schutz gegen immer raffiniertere digitale Spoofing-Angriffe. Da Technologien wie Deepfakes immer zugänglicher werden, ist die Fähigkeit, einen lebenden, anwesenden Menschen zuverlässig von einer digitalen Rekonstruktion, einer hochwertigen Maske oder einem aufgezeichneten Video zu unterscheiden, von entscheidender Bedeutung. Diese Fähigkeit stellt sicher, dass das digitale Remote-Onboarding angesichts der sich entwickelnden Bedrohungen eine vertrauenswürdige Methode der Identitätsüberprüfung bleibt und das Vertrauen in digitale Transaktionen und den digitalen Zugang aufrechterhalten wird.
3. Fähigkeit: Automatisierte visuelle Adressnachweisüberprüfung
Was wird möglich sein? CV-Systeme werden nicht nur Text per OCR lesen, sondern auch eingereichte Adressnachweisdokumente (wie Rechnungen von Versorgungsunternehmen oder Kontoauszüge) visuell analysieren. Sie können den Dokumententyp anhand des visuellen Layouts und des Brandings identifizieren, wichtige Informationsfelder (Name, Adresse, Datum) lokalisieren, Logos, Wasserzeichen und andere Sicherheitsdruckmerkmale visuell überprüfen und die allgemeine visuelle Integrität des Dokuments beurteilen, um sicherzustellen, dass es sich um einen echten physischen Scan und nicht – basierend auf visuellen Artefakten – um eine möglicherweise manipulierte digitale Datei bzw. einen Screenshot handelt.
Dies bedeutet das Ermöglichen einer schnelleren, effizienteren und einheitlichere Bearbeitung einer allgemeinen Anforderung in der Kundenidentifikation. Die Automatisierung der visuellen Analyse dieser unterschiedlichen Dokumente reduziert den manuellen Überprüfungsaufwand, beschleunigt die gesamte Onboarding-Zeit für den Kunden, senkt die Betriebskosten für das Unternehmen und wendet eine standardisierte Überprüfungslogik an, die eine bei manueller Überprüfung möglicherweise fehlende Konsistenz gewährleistet.
Diese drei Beispiele zeigen, wie die Fortschritte in der Computer Vision die KYC-Prüfung über einfache Überprüfungen hinaus auf ein Niveau der visuellen forensischen Analyse und Automatisierung bringen, das sich erheblich auf die Sicherheit, Effizienz und den Kampf gegen Finanzkriminalität auswirkt.
Blogbeitrag 25. April 2025:
Die Zukunft sehen: Computer Vision in der Schweiz – Wie geht es weiter?
von Kevin Lancashire

Computer Vision (CV) entwickelt sich rasant weiter und verändert die Art und Weise, wie Maschinen die Welt um sie herum verstehen, indem sie ihnen ermöglicht, visuelle Informationen zu „sehen“ und zu interpretieren. Wie Ihre detaillierte Analyse zeigt, entwickelt sich dieser Bereich der künstlichen Intelligenz (KI) von einer Spezialanwendung zu einer grundlegenden Technologie, die in den Bereichen Gesundheitswesen, Fertigung, Einzelhandel, Landwirtschaft und Sicherheit weltweit erhebliche Veränderungen bewirkt.
Wir haben gesehen, wie Länder wie die Vereinigten Staaten bei der groß angelegten Einführung und Kommerzialisierung führend sind, angetrieben durch massive Investitionen und den Fokus auf Marktumbrüche. Beispiele wie die kassenlosen Läden von Amazon Go oder die schnelle Schlaganfallerkennung von Viz.ai zeigen die potenziellen Auswirkungen einer breiten Einführung von CV.
Aber was ist mit der Schweiz? Unser Land zeichnet sich durch eine besondere Landschaft aus: Es ist weltweit bekannt für seine erstklassigen Forschungseinrichtungen wie die ETH Zürich und die EPFL, seine hochqualifizierten Arbeitskräfte und seinen Fokus auf hochwertige Präzisionsindustrien wie Pharmazeutik, Medizintechnik, Uhrenindustrie und Finanzwesen. Mit dem revidierten DSG verfügen wir zudem über einen starken Rahmen für den Datenschutz und einen einzigartigen, sektorspezifischen Ansatz für die Regulierung von KI, der sich gegen das horizontale KI-Gesetz der EU entschieden hat.
Dies bringt uns zu einer entscheidenden Frage für alle, die sich für Technologie, Wirtschaft oder die Zukunft der Innovation in der Schweiz interessieren:
Wie kann die Schweiz in Anbetracht ihrer einzigartigen Stärken und Herausforderungen die Computer-Vision-Technologie effektiv nutzen, um ihren Wohlstand und ihre Führungsposition in Schlüsselindustrien zu sichern?
Um diese Frage zu beantworten, muss man den schweizerischen Kontext genau betrachten und die Wege identifizieren, die für unser Ökosystem am sinnvollsten sind. Im Folgenden werden einige Schlüsselbereiche und Erkenntnisse aus der detaillierten Analyse vorgestellt:
1. Kapital aus der Präzisions- und Hochwertindustrie schlagen:
Die Exzellenz der Schweiz in Bereichen wie der Hochpräzisionsfertigung (einschließlich der Uhrenindustrie), der Pharmazie und der Medizintechnik bietet eine natürliche Heimat für fortschrittliche CV-Anwendungen. Wir sind führend in der Entwicklung hochspezialisierter Lösungen für:
Ultrapräzise Qualitätskontrolle: Wir gehen über die einfache Fehlererkennung hinaus, um mikroskopisch kleine Fehler zu erkennen, die für Uhrenkomponenten oder medizinische Geräte entscheidend sind. Unternehmen wie Alpvision setzen CV bereits zur Bekämpfung von Fälschungen bei Luxusgütern ein, und die ORIGYN Foundation wendet es zur Authentifizierung von Uhren an.
Fortschrittliche medizinische Bildanalyse: Nutzung unseres Fachwissens in den Bereichen Pharmazie und Gesundheitswesen zur Entwicklung von KI-gesteuerten Tools für die Diagnostik (wie die Arbeit von Roche in der digitalen Pathologie) oder die personalisierte Behandlungsplanung, aufbauend auf der von Institutionen wie dem SNF finanzierten Forschung.
Optimierte Logistik und Infrastruktur: Wie der Einsatz von KI bei der Gleisinspektion durch die SBB oder die Optimierung von Sortierzentren durch die Schweizerische Post zeigt, gibt es ein erhebliches Potenzial für den Einsatz von Bildverarbeitungssystemen zur Steigerung der Effizienz und Sicherheit in unseren kritischen Transport- und Logistiknetzen.
2. Technologieführerschaft in der Nische nutzen:
Anstatt zu versuchen, mit den globalen Giganten zu konkurrieren, kann sich die Schweiz durch die Entwicklung von CV-Spitzentechnologien in Nischenbereichen auszeichnen. Unsere Forschungseinrichtungen sind bereits stark in Bereichen wie Robotik (ANYbotics, Sevensense), 3D-Computer-Vision und potenziell führend in Edge AI und Explainable AI (XAI) – entscheidend für den Aufbau von Vertrauen und die Gewährleistung von Transparenz. Unternehmen wie LatticeFlow, die sich auf die Verbesserung von KI-Vision-Modellen konzentrieren, sind ein Beispiel für dieses Potenzial von Basistechnologien.
3. Vertrauen aufbauen und Datenschutz gewährleisten:
Der starke Datenschutzrahmen der Schweiz (DSG) und die kulturelle Betonung der Sicherheit können einen Wettbewerbsvorteil darstellen. Die regulatorischen Unterschiede zum EU-KI-Gesetz erhöhen zwar die Komplexität, versetzen uns aber auch in die Lage, CV-Lösungen zu entwickeln und anzubieten, die von Grund auf auf Datenschutz und Vertrauenswürdigkeit ausgelegt sind („privacy by design“). Dies könnte ein entscheidendes Unterscheidungsmerkmal sein, insbesondere bei sensiblen Anwendungen wie dem Gesundheitswesen, dem Finanzwesen (Identitätsprüfung durch PXL Vision) und der öffentlichen Sicherheit.
4. Strategische Investitionen und Zusammenarbeit:
Um die Lücke bei der Skalierung im Vergleich zu den USA zu schließen, sind gezielte Anstrengungen erforderlich:
Gezielte Finanzierung: Investoren sollten nicht nur auf die Quantität der Start-ups achten, sondern auch die hohe Qualität der Innovationen anerkennen, die von Schweizer Universitäten und Forschungslabors ausgehen, insbesondere in unseren industriellen Stärkefeldern.
Verbindungen zwischen Hochschulen und Industrie: Die Stärkung der Zusammenarbeit zwischen Forschungsinstitutionen (ETH, EPFL, SDSC) und Schweizer Unternehmen (einschliesslich KMU) ist für die Umsetzung von Spitzenforschung in praktische, kommerzielle Lösungen unerlässlich.
Regulierung meistern: Die politischen Entscheidungsträger müssen weiterhin auf klare, pragmatische und interoperable Regelungen hinarbeiten, die Innovationen unterstützen und gleichzeitig die Schweizer Standards für Datenschutz und Ethik aufrechterhalten.
Wie geht es jetzt weiter?
Die Schweiz ist gut positioniert, um eine führende Rolle einzunehmen, nicht unbedingt bei den meisten CV-Einsatzgebieten, aber bei den hochwertigsten, vertrauenswürdigsten und spezialisiertesten Anwendungen. Indem wir unsere F&E-Fähigkeiten auf unsere industriellen Stärken konzentrieren, die Zusammenarbeit im gesamten Ökosystem fördern, die Herausforderungen der Skalierung und Regulierung proaktiv angehen und Datenschutz und Vertrauen konsequent priorisieren, kann die Schweiz eine bedeutende und respektierte Rolle in der globalen Computer-Vision-Landschaft einnehmen.
Der Weg dorthin führt über kontinuierliches Lernen, strategischen Fokus und die Bereitschaft, in die grundlegenden Technologien und Talente zu investieren, die es uns ermöglichen werden, die Zukunft zu sehen und zu gestalten.
Lesen Sie unser Whitepaper: https://www.theadvice.ai/s/Computer-Vision-USA-to-Switzerland.pdf
Blogbeitrag 23. April 2025:
Sehen ist Erschaffen: Wie Computer Vision die menschliche Vorstellungskraft erweitert und Herausforderungen der realen Welt löst
von Kevin Lancashire

Die Computer Vision (CV), die sich früher hauptsächlich auf analytische Funktionen konzentrierte, vereinigt sich nun mit der menschlichen Kreativität und verändert grundlegend die Art und Weise, wie wir uns Probleme vorstellen und diese lösen. Dieser Wandel, der durch Fortschritte in der künstlichen Intelligenz (KI), insbesondere durch generative und multimodale Modelle, vorangetrieben wird, macht die KI nicht nur zu einem Werkzeug, sondern auch zu einem Katalysator für neue Ideen und zu einem kollaborativen Partner im kreativen Prozess.
Dieser Paradigmenwechsel ermöglicht innovative Ansätze für komplexe Herausforderungen, die über die einfache visuelle Interpretation hinausgehen und zur aktiven Gestaltung und Interaktion mit unserer Welt führen.
Entschlüsselung der Synergie: CV und der kreative Prozess
Im Kern ermöglicht Computer Vision Maschinen, visuelle Daten zu interpretieren, und entwickelt sich von der einfachen Bildklassifizierung bis hin zum ausgefeilten Verständnis von Szenen. Der entscheidende Schritt nach vorn ist die generative Fähigkeit, die es Modellen ermöglicht, neue visuelle Inhalte zu synthetisieren. Dies wird unterstützt durch:
-
Generative Modelle: Wie GANs und Diffusionsmodelle, die in der Lage sind, realistische und völlig neue Bilder und Stile zu erstellen.
-
Grundlegende Modelle und selbstüberwachtes Lernen: Große Modelle, die auf umfangreichen Datensätzen trainiert wurden und robuste Darstellungen und Verallgemeinerungsfähigkeiten bieten, die den Zugang zu fortgeschrittenen Lebensläufen demokratisieren.
Die menschliche Kreativität, die sich dadurch auszeichnet, dass sie durch divergierendes und konvergentes Denken neue und nützliche Ideen hervorbringt, findet in dieser weiterentwickelten Computer Vision einen starken Partner. Die Synergie entsteht durch:
-
Verstärkung: Automatisierung mühsamer Aufgaben, die den menschlichen Schöpfer für die Konzeptualisierung auf höherer Ebene freisetzen.
-
Inspiration/Erkundung: Generative Modelle erforschen riesige Möglichkeitsräume und präsentieren unerwartete Ergebnisse, die neue Wege aufzeigen.
-
Kollaboration: Menschen legen Ziele fest und geben ihr Urteilsvermögen ab, während KI generative und analytische Fähigkeiten beisteuert, was zu Ergebnissen führt, die keiner von beiden allein erreichen könnte.
Die Integration multimodaler KI, die Bild-, Sprach- und andere Daten verarbeitet, ist von entscheidender Bedeutung und ermöglicht eine intuitive, natürlichsprachliche Interaktion mit hochentwickelten Computer-Vision-Werkzeugen.
Ein schöpferisches Werkzeugset: Computer-Vision-Techniken in Aktion
Ein breites Spektrum von CV-Techniken bildet dieses neue kreative Toolkit:
-
Visuelle Synthese und Manipulation: Generative Modelle (GANs, Diffusionsmodelle) für die Erstellung neuer visueller Darstellungen und Neural Style Transfer für die Neudefinition der Ästhetik durch Anwendung künstlerischer Stile.
-
Gestaltung interaktiver Erlebnisse: Objekt-, Bewegungs- und Gesichtserkennung in Echtzeit für dynamische Kunstinstallationen und reaktionsfähige Umgebungen, die auf den Betrachter reagieren.
-
Ausweitung kreativer Bereiche: KI-Modelle zur Analyse und Erzeugung von Musik, generative KI (NeRFs, Gaussian Splatting) zur Gestaltung virtueller und physischer 3D-Welten und KI-Videogenerierung für dynamisches Storytelling.
Neue Entwicklungen in den Bereichen effiziente Transformatoren, selbstüberwachtes Lernen und erklärbare KI (XAI) machen diese leistungsstarken Modelle praktischer, verständlicher und zugänglicher für eine breite kreative Anwendung.
Innovative Lösungen: Anwendung der kreativen Computervision für Probleme der realen Welt
Das größte Potenzial liegt in der Anwendung dieser kreativen CV-Fähigkeiten zur Bewältigung dringender globaler Herausforderungen:
-
Verbesserung der Barrierefreiheit: Stellen Sie sich einen „Dynamic Sensory Narrator“ vor, der multimodale KI in Echtzeit einsetzt, um personalisierte, kontextabhängige Umgebungserzählungen für sehbehinderte Nutzer zu erstellen, oder einen „Adaptive Interface Sculptor“, der digitale Schnittstellen dynamisch auf der Grundlage der Echtzeit-Anwendungsbedürfnisse eines Nutzers umgestaltet.
-
Förderung der ökologischen Nachhaltigkeit: Ein „Eco-Narrative Visualizer“ könnte komplexe Umweltdaten in intuitive, interaktive Visualisierungen umwandeln, während ein „Hyper-Spectral Waste Sorter & Designer“ präzise Abfallanalysen mit kreativen Upcycling-Lösungen verbinden könnte.
-
Bewahrung und Wiederbelebung des kulturellen Erbes: Ein „Living Archive Generator“ könnte interaktive 3D-Umgebungen erstellen, die den historischen Kontext von Artefakten visualisieren, und ein „AI Restoration Artisan“ könnte stilistisch plausible Ergänzungen für beschädigte Kunstwerke vorschlagen.
-
Beschleunigung der wissenschaftlichen Entdeckung: Ein „Generative Hypothesis Imager“ könnte neue visuelle Hypothesen aus wissenschaftlichen Daten synthetisieren, und ein „Interactive Multimodal Discovery Canvas“ könnte eine intuitive Erkundung integrierter, multimodaler wissenschaftlicher Datensätze ermöglichen.
Diese „Out-of-the-Box“-Konzepte nutzen die generativen und interaktiven Fähigkeiten von CV, um neue Möglichkeiten der Wahrnehmung und Interaktion mit komplexen Informationen in verschiedenen Bereichen zu schaffen.
Schlussfolgerung: Die Zukunft der Co-Kreation
Die Entwicklung von Computer Vision markiert einen tiefgreifenden Wandel hin zu einer gemeinsamen Entwicklung von Mensch und Maschine. Während das Potenzial zur Steigerung der Kreativität und zur Lösung realer Probleme immens ist, ist dabei die Berücksichtigung ethischer Aspekte von größter Bedeutung. Fragen der Voreingenommenheit, der Urheberschaft, der Privatsphäre, der Verdrängung von Arbeitsplätzen und des gleichberechtigten Zugangs erfordern einen ständigen Dialog und eine proaktive Steuerung.
Die Zukunft weist in Richtung intuitiver, kontrollierbarer und multimodaler KI-Systeme, die sich nahtlos in kreative Arbeitsabläufe integrieren lassen. Durch interdisziplinäre Zusammenarbeit und verantwortungsvolle Innovation kann die Computer Vision uns nicht nur helfen, unsere Welt zu sehen und zu verstehen, sondern auch aktiv an der Gestaltung einer besseren Zukunft mitzuwirken.
Lesen Sie unser Whitepaper.
Blogbeitrag 12. April 2025:
Hyper-Spectral CV stellt sich den Herausforderungen der Materialsortierung
von Kevin Lancashire

In diesem Beitrag wagen wir uns über das vertraute Gebiet der RGB-Bilder und der Standard-Objekterkennung hinaus. Wir untersuchen, wie die Ausweitung von Computer Vision auf den hyper-spektralen Bereich leistungsstarke Fähigkeiten in einer anspruchsvollen, realen Anwendung freisetzt: in der fortschrittlichen Müllsortierung und dem Recycling.
Während CV bei der Identifizierung von Objekten auf der Grundlage von Form und sichtbaren Lichtmustern hervorragende Dienste leistet, sehen viele Materialien für eine Standardkamera ähnlich aus, was zu Verunreinigungen in Recyclingströmen führt. Die hyperspektrale Bildgebung (HSI) bietet eine Lösung, indem sie Daten in Hunderten von schmalen, zusammenhängenden Wellenlängenbändern erfasst, die das menschliche Auge oder typische Sensoren weit übertreffen.
Die zentrale CV-Herausforderung: Dekodierung von Spektralsignaturen
Jedes Material interagiert mit dem Licht in diesen Bändern auf einzigartige Weise und erzeugt so eine hochdimensionale Spektralsignatur – quasi einen einzigartigen Fingerabdruck. Die CV-Aufgabe hier umfasst:
- Datenerfassung: Erfassung von hochauflösenden hyper-spektralen Datenwürfeln von Gegenständen auf einem sich schnell bewegenden Förderband.
- Merkmalsextraktion und Analyse: Verarbeitung dieser umfangreichen, hochdimensionalen Daten, um die einzigartige spektrale Signatur für jedes Pixel oder Objektsegment zu isolieren.
- Klassifizierung: Einsatz von Modellen des maschinellen Lernens (häufig Techniken, die sich für die Verarbeitung hochdimensionaler Daten eignen, wie SVMs, Random Forests oder in zunehmendem Maße auch Deep-Learning-Ansätze wie CNNs, die für Spektraldaten angepasst wurden), die auf umfangreichen Bibliotheken trainiert wurden, um Materialien auf der Grundlage ihrer Signaturen mit extrem hoher Präzision zu klassifizieren. Dies ermöglicht die Unterscheidung zwischen verschiedenen Kunststoffpolymeren (PET, HDPE, PVC, PP), Papiersorten, organischen Stoffen und Verunreinigungen, die visuell nicht zu unterscheiden sind.
Von der Analyse zur Aktion: Der Sortierprozess
Basierend auf den Echtzeit-Klassifizierungsergebnissen des ML-Modells löst das System präzise Aktuatoren aus (z. B. gezielte Luftdüsen, Robotermanipulatoren), um die Materialien physisch in hochreine Ströme zu trennen.
Warum hyper-spektrales CV hier disruptiv ist:
- 🎯 Unerreichte Spezifität: Ermöglicht eine Materialidentifizierung und -reinheit, die mit herkömmlichen Bildverarbeitungs- oder Nahinfrarotsystemen (NIR) allein nicht möglich ist, was für hochwertiges Recycling entscheidend ist.
- 📈 Verbesserte Automatisierung und Effizienz: Ermöglicht eine vollautomatische Sortierung mit hohem Durchsatz und überwindet die Einschränkungen und Kosten der manuellen Prüfung.
- ♻️ Ermöglicht echte Kreislaufwirtschaft: Erzeugt einen Rohstoff, der rein genug ist für anspruchsvolle Recyclinganwendungen in geschlossenen Kreisläufen, wodurch die wirtschaftliche Tragfähigkeit der Kreislaufwirtschaft gefördert wird.
- 📊 Reichhaltige Datenerzeugung: Die Spektraldaten selbst bieten Einblicke in Materialabbau, Zusammensetzungsschwankungen und Prozessqualitätskontrolle.
Die Grenzen verschieben
Die hyperspektrale Bildgebung in Kombination mit hochentwickelter ML stellt einen bedeutenden Sprung für CV in industriellen Anwendungen dar. Die Herausforderung besteht nicht mehr nur darin, Objekte zu sehen„, sondern die Materialzusammensetzung durch die Interaktion des Lichts zu verstehen“. Zwar gibt es Herausforderungen wie die Intensität der Datenverarbeitung und die Systemkosten, doch die Vorteile für die Nachhaltigkeit und das Ressourcenmanagement treiben die Akzeptanz dieser Technologie voran.
Diese Anwendung unterstreicht die Möglichkeiten, die sich aus dem Einsatz von Computer Vision jenseits herkömmlicher Erfassungsmodalitäten zur Lösung komplexer Probleme ergeben.
Blogbeitrag 5. April 2025:
Visuelle Prozessautomatisierung: Liefert sie jetzt echte Ergebnisse? Ein Blick ins Jahr 2025 und darüber hinaus
Von Kevin Lancashire

Angetrieben von leistungsstarken KI-Modellen wie Vision Transformers (ViTs), die in der Lage sind, ein nuanciertes Bildverständnis zu erreichen, das frühere Methoden übertrifft, und dem praktischen Einsatz von Echtzeit-Analysen über Edge Computing, bewegt sich die Automatisierung visueller Prozesse schnell aus den Forschungslabors in konkrete Anwendungen. Wir sehen KI-gesteuerte Kameras, die mikroskopisch kleine Defekte an Produktionslinien aufspüren, Algorithmen, die Mediziner bei der Analyse komplexer Scans unterstützen, und Logistiksysteme, die Routen auf der Grundlage visueller Echtzeitdaten optimieren. Dies ist nicht nur eine Spekulation über die Zukunft; Maschinen interpretieren zunehmend visuelle Informationen, um komplexe Aufgaben zu erfüllen, was zu messbaren Effizienzsteigerungen führt und neue Möglichkeiten eröffnet.
Diese Beschleunigung wirft eine entscheidende Frage für Unternehmen und Technologen auf: Hält dieser Bereich nun konsequent sein transformatives Versprechen, und wie stabil sind die Aussichten für die kommenden Jahre?
Das Versprechen verfestigt sich zur Realität
Basierend auf den aktuellen Implementierungen und der Innovationspipeline deuten die Beweise stark darauf hin, dass die visuelle Automatisierung einen greifbaren Wert liefert und ihr Potenzial weiter zunimmt. Hier ist die Grundlage für diesen positiven Ausblick:
-
Vertieftes Verständnis: Vision Transformers (ViTs) sind nicht nur theoretisch; sie ermöglichen Systeme, die Bildkontext und -beziehungen analysieren und über die einfache Erkennung hinausgehen, um eine anspruchsvollere Automatisierung in dynamischen Umgebungen zu ermöglichen.
-
Überwindung von Datenengpässen: Generative KI wird aktiv genutzt, um synthetische Datensätze zu erstellen und so nachweislich den Zeit- und Kostenaufwand für das Training robuster Modelle zu verringern, vor allem wenn die Erfassung umfangreicher markierter Daten aus der realen Welt unpraktisch oder teuer ist.
-
Intelligenz an der Quelle: Edge Computing ist keine Nische mehr. Die visuelle Verarbeitung erfolgt jetzt direkt auf Geräten wie Inspektionskameras, autonomen Drohnen und intelligenten Fahrzeugen und ermöglicht die unmittelbare Entscheidungsfindung, die für wirklich automatisierte Systeme erforderlich ist.
-
Geringerer Aufwand für die Kennzeichnung: Selbstüberwachte Lerntechniken erweisen sich als effektiv, wenn es darum geht, dass Modelle leistungsstarke Darstellungen aus nicht beschrifteten visuellen Daten erlernen, wodurch der bisher erforderliche manuelle Beschriftungsaufwand erheblich reduziert wird.
-
Räumliches Vorstellungsvermögen: Fortschritte in der 3D-Vision führen zu Robotern, die Objekte mit größerer Geschicklichkeit navigieren und manipulieren können, und zu AR-Systemen, die nahtlos mit der physischen Welt interagieren.
Diese technologischen Realitäten schlagen sich direkt in beobachteten Vorteilen nieder: quantifizierbare Kostensenkungen durch automatisierte Qualitätssicherung, verbesserter Durchsatz in Fertigung und Logistik, verbesserte Sicherheitssysteme und die Entwicklung neuartiger Diagnosewerkzeuge und Kundenerfahrungen.
Erwartungshaltung: Der Weg zu einer breiten Akzeptanz
Die Erfolge sind zwar real, aber um diese Fähigkeiten universell einsetzen zu können, müssen die praktischen Hürden anerkannt werden:
-
Implementierungskosten und -komplexität: Modernste Modelle erfordern oft eine beträchtliche Rechenleistung, und die Bereitstellung von Systemen (insbesondere am Rande der Wertschöpfungskette) ist mit Hardware-Investitionen und einer komplexen Integration in bestehende Arbeitsabläufe verbunden. Plug-and-Play stehen nicht immer zur Verfügung.
-
Daten-Nuancen: Auch wenn neue Techniken hilfreich sind, bleiben Daten der Schlüssel. Die Sicherstellung der Datenqualität, die Beseitigung von Verzerrungen und die Wahrung der Privatsphäre sind entscheidende Hürden.
-
Das Problem der „letzten Meile“: Die Integration von KI in spezifische, reale Prozesse erfordert Fachwissen, robuste Technik und strenge Tests. Was im Labor funktioniert, muss sich in der Praxis bewähren.
-
Vertrauen und Regulierung: Insbesondere bei kritischen Anwendungen wie dem Gesundheitswesen und dem autonomen Fahren dauert es seine Zeit, Vertrauen aufzubauen und die behördlichen Genehmigungen zu durchlaufen.
Das Fazit: Jetzt liefern, für mehr bereit sein, erfordert strategisches Handeln
Hält die visuelle Prozessautomatisierung also, was wir erwarten? In zunehmendem Maße, ja. Sie liefert konkrete Ergebnisse in verschiedenen Sektoren. Sieht es vielversprechend aus? Auf jeden Fall. Die Innovationspipeline bleibt stark und verspricht noch größere Möglichkeiten.
Das Tempo und der Umfang des künftigen Erfolgs hängen jedoch von der Bewältigung der praktischen Realitäten ab. Die Herausforderungen machen deutlich, dass eine strategische Planung, gezielte Investitionen, realistische Zeitpläne für die Einführung und eine Konzentration auf Anwendungsfälle mit klarem, messbarem Nutzen erforderlich sind.
Unternehmen müssen prüfen, wo die visuelle Automatisierung bestimmte Probleme jetzt lösen kann, und sich gleichzeitig auf die nächste Welle von Fortschritten vorbereiten. Die Ära der intelligenten visuellen Systeme ist in vollem Gange, und es ist absehbar, dass sie für diejenigen, die sich strategisch engagieren, Effizienz und Leistungsfähigkeit in allen Bereichen neu definieren wird.
Sind Sie bereit zu erkunden, wie visuelle Automatisierung, angetrieben durch KI und Edge Computing, einen greifbaren Wert für Ihre spezifischen Anforderungen schaffen kann? Lassen Sie uns reden. Kevin Lancashire Kim Vemula
Blogbeitrag 30. März 2o25: The Advice win with AI:
Die 3 größten Herausforderungen der Computer Vision – und wie Advice AI sie löst.
Von Kevin Lancashire
Liebe Kolleginnen und Kollegen,
Computer Vision hat das Potenzial, zahlreiche Branchen zu revolutionieren. Doch die Implementierung dieser Technologie stellt Unternehmen oft vor Herausforderungen, die ihnen Kopfzerbrechen bereiten. Wir von The Advice AI verstehen diese Probleme und bieten maßgeschneiderte Lösungen, um Ihre Computer-Vision-Projekte erfolgreich zu machen.
Die 3 häufigsten Probleme beim Computer Vision:
Datenqualität und -menge:
Computer-Vision-Modelle benötigen große Mengen an hochwertigen Trainingsdaten, um genaue Ergebnisse zu liefern. Die Beschaffung und Verarbeitung dieser Daten kann zeitaufwändig und kostspielig sein. Außerdem können verzerrte oder unvollständige Daten zu ungenauen Vorhersagen führen.
Die Lösung von Advice AI:
Unsere Plattform bietet fortschrittliche Algorithmen zur Datenerweiterung und -bereinigung, um die Qualität und Quantität Ihrer Trainingsdaten zu optimieren. Wir unterstützen Sie bei der Erstellung von Datensätzen und bieten auch Dienstleistungen für die Datenerfassung und -auswertung an.
Herausforderungen im Zusammenhang mit der Rechenleistung:
Bildverarbeitungsanwendungen erfordern oft erhebliche Rechenressourcen, insbesondere für die Echtzeitverarbeitung und komplexe Modelle. Dies kann zu hohen Hardwarekosten und Leistungsproblemen führen.
Die Lösung von Advice AI:
Durch unsere Arbeit in Indien haben wir Zugang zu einem sehr hohen Niveau an Fachwissen in der IT-Entwicklung. Dies ermöglicht uns, Entwicklungen im Vergleich zu vielen anderen Wettbewerbern kostengünstig und hocheffizient voranzutreiben. Unser Angebot umfasst optimierte Algorithmen und den Einsatz von Cloud-basierten Lösungen sowie unsere speziell auf unsere Kunden zugeschnittenen Anwendungen und Plattformen. Damit sind wir in der Lage, auch komplexe Computer-Vision-Anwendungen effizient und kostengünstig zu realisieren.
Implementierung und Integration:
Die Integration von Bildverarbeitungsmodellen in bestehende Systeme kann komplex sein und erfordert spezielle Kenntnisse. Auch die Anpassung der Modelle an spezifische Anwendungsfälle kann eine Herausforderung darstellen.
Die Lösung von Advice AI:
Unser Expertenteam verfügt über umfangreiche Erfahrung in der Entwicklung und Integration von Computer-Vision-Lösungen. Wir bieten maßgeschneiderte Lösungen und unterstützen Sie bei der reibungslosen Integration in Ihre bestehenden Arbeitsabläufe. Wir bieten auch KI-Audits an, um die Sicherheit und Effizienz der eingesetzten Systeme zu gewährleisten.
Sind Sie bereit, die Herausforderungen der Computer Vision zu meistern? Kontaktieren Sie uns noch heute für ein kostenloses Beratungsgespräch und finden Sie heraus, wie The Advice AI Ihr Unternehmen unterstützen kann.
Implementierung in Indien:
Von unseren Büros in Basel und St. Gallen aus bietet Day One kompetente Beratungsleistungen für Schweizer Firmen an. Wir nutzen die qualifizierten IT-Ressourcen in Indien, um eine schnelle, qualitativ hochwertige Entwicklung und wettbewerbsfähige Preise für innovative Lösungen zu gewährleisten.
Referenzen: www.theadvice.ai
Bitte kontaktieren Sie uns jederzeit.
Kevin Lancashire, kevin.lancashire@advice.ai
Blogbeitrag 29. März 2025: The Advice win with AI:
Schluss mit dem Parkplatzproblem: Intelligente Technologie verändert die urbane Mobilität
Kennen Sie das Gefühl? In einer belebten Stadt einen Häuserblock nach dem anderen zu umrunden und verzweifelt nach einem Parkplatz zu suchen? Der Stress, die verschwendete Zeit, die wachsende Frustration darüber, dass man möglicherweise zu spät kommt – das ist eine häufige Erfahrung in städtischen Umgebungen weltweit.
Aber was wäre, wenn es einen intelligenteren Weg gäbe?
Die gute Nachricht ist, dass sich eine transformative Lösung abzeichnet, die auf den Fortschritten der Computer Vision (CV) und des maschinellen Lernens (ML) beruht: intelligente Parksysteme. Diese intelligenten Systeme sollen die mit dem Parken verbundenen Ängste abbauen und das Leben in der Stadt wesentlich reibungsloser und effizienter gestalten.
Wie funktioniert das?
Das Herzstück des intelligenten Parkens ist die Fähigkeit, die Verfügbarkeit von Parkplätzen zu sehen„ und vorherzusagen“. Computer Vision fungiert als „Auge“ des Systems, das mit Hilfe von Kameras die Parkplätze auf den Straßen und in den Garagen überwacht. Diese Technologie erkennt, ob ein Platz besetzt oder frei ist. Die Nummernschilderkennung (LPR) fügt eine weitere Funktionsebene für die Zugangskontrolle und die Bezahlung hinzu.
Die Belegungsdaten werden dann an eine zentrale Plattform übermittelt, die einen umfassenden Überblick über die Verfügbarkeit von Parkplätzen in der ganzen Stadt bietet. Algorithmen des maschinellen Lernens analysieren diese Echtzeitdaten zusammen mit historischen Trends, um die zukünftige Verfügbarkeit vorherzusagen und sogar die Parkdauer zu schätzen.
Das Benutzererlebnis: Parken leicht gemacht
Stellen Sie sich vor, Sie nähern sich einem Stadtzentrum. Anstatt ziellos durch die Gegend zu fahren, öffnen Sie eine spezielle Anwendung zum Parken in der Stadt auf Ihrem Smartphone oder nutzen eine integrierte Funktion in einer Navigations-App. Eine intuitive Karte zeigt in Echtzeit die Verfügbarkeit von Parkplätzen in der Nähe Ihres Ziels an. Freie Plätze sind deutlich gekennzeichnet, und bei Parkhäusern können Sie die aktuelle Belegungszahl ablesen. Einige fortschrittliche Systeme bieten sogar Vorhersagen über die zukünftige Verfügbarkeit.
Sie wählen Ihre bevorzugte Option aus, und die App navigiert Sie direkt zum gewünschten Ort. Diese direkte Führung reduziert den Zeitaufwand für die Suche erheblich und minimiert den Stress.
Die greifbaren Vorteile:
Die Einführung von intelligenten Parksystemen bringt zahlreiche Vorteile mit sich:
- Schnelleres Finden von Parkplätzen: Autofahrer werden direkt zu einem freien Parkplatz geleitet, wodurch Zeitverluste vermieden werden.
- Weniger unerwartete Verspätungen: Durch die vorhersehbare Verfügbarkeit von Parkplätzen werden die Ankunftszeiten zuverlässiger.

Durchschnittszeit, die in diesen Städten für die Parkplatzsuche pro Jahr verwendet werden.
Blogbeitrag 24. März 2025: The Advice win with AI:
3D Vision: Die Welt in einer neuen Dimension
Wir leben in einer 3D-Welt, doch seit Jahrzehnten beschränkt sich unsere Interaktion mit der Technik weitgehend auf 2D-Bildschirme. Das ändert sich gerade dank der Fortschritte in der 3D-Vision, einem Bereich, der vor Potenzial nur so strotzt und die Art und Weise, wie wir mit Maschinen interagieren und wie Maschinen mit der Welt interagieren, neu gestaltet. Dabei geht es nicht nur um ausgefallene Grafiken, sondern um die Entwicklung von Technologien, die ihre Umgebung wirklich verstehen und auf sie reagieren.
Was ist 3D-Vision?
Einfach ausgedrückt: 3D-Vision (auch bekannt als Computer Vision mit Tiefenwahrnehmung) ermöglicht es Computern, die Welt in drei Dimensionen zu „sehen“, so wie wir es tun. Anstatt nur ein flaches Bild zu erkennen, können 3D-Vision-Systeme die Form, Größe, Position und Bewegung von Objekten im Raum erfassen. Erreicht wird dies durch verschiedene Technologien wie:
- Stereo-Vision: Verwendet zwei oder mehr Kameras, um das menschliche Binokularsehen zu imitieren, und berechnet die Tiefe durch den Vergleich der geringen Unterschiede in den Bildern.
- Strukturiertes Licht: Projiziert ein bekanntes Lichtmuster (wie ein Gitter) auf eine Szene und analysiert, wie das Muster verzerrt wird, um die Tiefe zu bestimmen.
- Lichtlaufzeit (Time-of-Flight, ToF): Misst die Zeit, die das Licht (in der Regel Infrarot) benötigt, um von einem Objekt abzuprallen und zum Sensor zurückzukehren, und berechnet anhand dieser Zeit die Entfernung.
- LiDAR (Light Detection and Ranging): Ähnlich wie ToF, aber mit Laserimpulsen, um eine sehr detaillierte 3D-Karte der Umgebung zu erstellen.

3D-LiDAR-Karte von Winterthur (By: Ephramac CC-BY SA 4.0)
Wie wirkt sich 3D-Vision auf den Benutzer aus? (Die Vorteile)
Die Auswirkungen der 3D-Vision sind tiefgreifend und erstrecken sich auf unzählige Anwendungen:
- Verbesserte Robotik: Mit 3D-Vision ausgestattete Roboter können in komplexen Umgebungen navigieren, Objekte präzise manipulieren und sicherer und intuitiver mit Menschen interagieren. Man denke nur an kollaborative Roboter (Cobots), die in Fabriken an der Seite von Menschen arbeiten, oder an chirurgische Roboter, die heikle Eingriffe mit unvergleichlicher Präzision durchführen.
- Autonome Fahrzeuge: 3D-Sehen ist für selbstfahrende Autos von entscheidender Bedeutung, da es ihnen ermöglicht, die Straße, Hindernisse, Fußgänger und andere Fahrzeuge in 3D wahrzunehmen, was eine sichere Navigation ermöglicht.
- Verbesserte Augmented Reality (AR) und Virtual Reality (VR): 3D-Vision macht AR- und VR-Erlebnisse weitaus realistischer und eindringlicher. AR-Anwendungen können virtuelle Objekte akkurat über die reale Welt legen, während VR die Bewegungen des Benutzers besser verfolgen und ein stärkeres Gefühl der Präsenz erzeugen kann.
- Präzise Messungen und Inspektionen: In Branchen wie der Fertigung und dem Bauwesen ermöglicht die 3D-Vision eine automatisierte Qualitätskontrolle, genaue Dimensionsmessungen und die Erkennung von Defekten.
- Gestenerkennung und -steuerung: 3D-Vision kann Hand- und Körperbewegungen genau verfolgen und ermöglicht so eine intuitive gestenbasierte Steuerung von Geräten und Anwendungen.
- Biometrische Sicherheit: Die 3D-Gesichtserkennung ist weitaus sicherer als 2D-Methoden und damit ideal für die Authentifizierung und Zugangskontrolle.
- Fortschritte im Gesundheitswesen: Von der 3D-Bildgebung für die Diagnostik bis hin zur Unterstützung von Roboteroperationen – 3D-Vision revolutioniert die medizinischen Verfahren und die Patientenversorgung.
- Einzelhandel und E-Commerce: Virtuelle Anproben von Kleidung und Accessoires, personalisierte Produktempfehlungen und automatische Kassensysteme werden durch 3D-Vision unterstützt.
- Kartierung und Vermessung: Drohnen und andere Plattformen, die mit 3D-Vision ausgestattet sind, können hochdetaillierte 3D-Karten des Geländes, von Gebäuden und der Infrastruktur erstellen.
Welche Probleme löst die 3D-Vision?
- Mangelndes räumliches Vorstellungsvermögen: 2D-Vision-Systeme haben Schwierigkeiten, Tiefe und räumliche Beziehungen zu verstehen. 3D-Vision löst diese grundlegende Einschränkung und ermöglicht es Maschinen, auf sinnvollere Weise mit der Welt zu interagieren.
- Einschränkungen bei der Automatisierung: Viele Aufgaben erfordern für die Automatisierung eine 3D-Wahrnehmung. 3D-Vision eröffnet neue Möglichkeiten für die Automatisierung von Aufgaben in der Fertigung, Logistik, Landwirtschaft und anderen Bereichen.
- Sicherheitsaspekte: In Anwendungen wie der Robotik und dem autonomen Fahren ist 3D-Vision entscheidend für die Gewährleistung der Sicherheit, da sie eine genaue Wahrnehmung der Umgebung ermöglicht.
- Ineffizienz bei Inspektionen: Manuelle Inspektionen können zeitaufwändig und fehleranfällig sein. 3D-Vision automatisiert Prüfprozesse und verbessert so die Genauigkeit und Effizienz.
- Benutzererfahrung: Bietet ein intensiveres und interaktiveres Erlebnis.
Das bahnbrechende Element: Demokratisierung der 3D-Wahrnehmung
Das bahnbrechende Element ist die zunehmende Zugänglichkeit und Erschwinglichkeit der 3D-Vision-Technologie. Was einst auf industrielle High-End-Anwendungen beschränkt war, wird nun auch für kleinere Unternehmen und sogar für Verbraucher verfügbar. Dies wird angetrieben durch:
- Günstigere Sensoren: Die Kosten für 3D-Sensoren (wie LiDAR und ToF-Kameras) sind erheblich gesunken, so dass sie für ein breiteres Spektrum von Anwendungen in Frage kommen.
- Verbesserte Software und Algorithmen: Fortschritte im Bereich des maschinellen Lernens und der Computer-Vision-Algorithmen haben die 3D-Datenverarbeitung effizienter und genauer gemacht.
- Cloud Computing: Cloud-Plattformen bieten die für die Verarbeitung großer 3D-Datensätze erforderliche Rechenleistung und machen 3D-Vision für Entwickler leichter zugänglich.
- Integration in bestehende Technologien: Die 3D-Vision wird zunehmend in Smartphones, Tablets und andere Alltagsgeräte integriert.
Diese Demokratisierung bedeutet, dass wir uns von einer Welt, in der 3D-Vision eine Nischentechnologie ist, zu einer Welt entwickeln, in der sie eine allgegenwärtige Fähigkeit ist, die die Art und Weise, wie wir mit der digitalen und physischen Welt interagieren, grundlegend verändert.
Die wichtigsten Triebkräfte der 3D-Vision-Entwicklung:
- Tech-Giganten: Unternehmen wie Apple, Google, Microsoft, Amazon und Meta investieren massiv in die Forschung und Entwicklung von 3D-Vision und integrieren sie in ihre Produkte und Plattformen.
- Automobilhersteller: Automobilhersteller wie Tesla, Waymo, GM, Ford und andere treiben die Innovation im Bereich 3D-Vision für autonome Fahrzeuge voran.
- Robotik-Unternehmen: Unternehmen, die auf Industrieroboter, chirurgische Roboter und Serviceroboter spezialisiert sind (z. B. Boston Dynamics, ABB, Intuitive Surgical), treiben die Grenzen der 3D-Vision für Roboteranwendungen voran.
- Sensorhersteller: Unternehmen wie Sony, Velodyne, Ouster und Intel entwickeln fortschrittliche 3D-Sensoren, die kleiner, günstiger und leistungsfähiger sind.
- Software- und KI-Unternehmen: Zahlreiche Start-ups und etablierte Unternehmen entwickeln spezielle Software und KI-Algorithmen für 3D-Vision-Anwendungen.
- Forschungsinstitutionen: Universitäten und Forschungslabors auf der ganzen Welt betreiben Spitzenforschung in den Bereichen Computer Vision, Robotik und verwandten Gebieten.
Job-Talente werden gebraucht:
Das rasche Wachstum der 3D-Vision führt zu einem starken Anstieg der Nachfrage nach qualifizierten Fachkräften. Zu den wichtigsten Aufgaben und Talenten gehören:
- Computer-Vision-Ingenieure: Experten für die Entwicklung von Algorithmen zur Verarbeitung und Interpretation von 3D-Bilddaten. Ein tiefes Verständnis von Bildverarbeitung, maschinellem Lernen (insbesondere Deep Learning) und 3D-Geometrie ist unerlässlich.
- Robotik-Ingenieure: Fachleute, die Roboter entwerfen, bauen und programmieren, die 3D-Vision für Navigation, Manipulation und Interaktion nutzen. Kenntnisse in den Bereichen Robotik, Steuerungssysteme und Sensorintegration sind von entscheidender Bedeutung.
- Softwareentwickler (3D-Grafik/AR/VR): Entwickler, die Anwendungen erstellen, die 3D-Vision für Augmented Reality, Virtual Reality und andere interaktive Erlebnisse nutzen. Kenntnisse in der 3D-Grafikprogrammierung, in Game Engines (wie Unity und Unreal Engine) und in AR/VR-Entwicklungsplattformen sind erforderlich.
- Ingenieure für maschinelles Lernen: Spezialisten für die Entwicklung und das Training von maschinellen Lernmodellen für 3D-Objekterkennung, Szenenverständnis und andere 3D-Vision-Aufgaben. Gute Kenntnisse in Deep Learning, Datenanalyse und Modelloptimierung sind erforderlich.
- Datenwissenschaftler: Fachleute, die große 3D-Datensätze sammeln, analysieren und interpretieren, um die Leistung von 3D-Vision-Systemen zu verbessern. Kenntnisse in Data Mining, statistischer Analyse und maschinellem Lernen sind unerlässlich.
- Hardware-Ingenieure (Sensorentwicklung): Ingenieure, die die Hardwarekomponenten von 3D-Vision-Systemen entwerfen und entwickeln, wie z. B. Kameras, LiDAR-Sensoren und Verarbeitungseinheiten. Fachwissen in den Bereichen Optik, Elektronik und eingebettete Systeme ist entscheidend.
- Ingenieure für eingebettete Systeme: Spezialisten, die die Software und Firmware entwickeln, die auf der 3D-Vision-Hardware läuft. Erfahrung mit Echtzeitbetriebssystemen, eingebetteter Programmierung und Sensorschnittstellen ist wichtig.
- Wahrnehmungsingenieure: Eine spezialisierte Rolle, die sich auf die gesamte Wahrnehmungspipeline für autonome Systeme (insbesondere Fahrzeuge) konzentriert, einschließlich Sensorfusion, Objektverfolgung und Szenenverständnis.
Die Zukunft ist 3D, und diejenigen, die in der Lage sind, 3D-Vision-Systeme zu entwickeln und zu nutzen, werden sehr gefragt sein. Es ist ein Feld mit vielen Möglichkeiten für Innovation und Einfluss.
Blogbeitrag 7. März 2025: The Advice – win with AI: Whitepaper: Den Bias in Gesichtserkennungssystemen konfrontieren

Die Gesichtserkennungstechnologie (FRT) hat die moderne Gesllschaft schnell durchdrungen und findet Anwendungen in verschiedenen Bereichen, von der banalen Aufgabe des Entsperrens von Smartphones bis hin zur kritischen Funktion zur Verstärkung der Sicherheitsmaßnahmen an Flughäfen und Grenzübergängen. Befürworter betonen oft das Potenzial der Technologie, die öffentliche Sicherheit zu erhöhen und verschiedene Prozesse zu rationalisieren, aber es mehren sich auch die Stimmen, die Bedenken über die ethischen Auswirkungen dieser Technologie äußern, insbesondere über die Neigung, bestehende gesellschaftliche Vorurteile aufrechtzuerhalten und zu verstärken. Dieser Artikel befasst sich mit der Problem der Voreingenommenheit in Gesichtserkennungssystemen, untersucht seine Ursprünge, erforscht die realen und bewertet mögliche Strategien zur Abschwächung dieses Bias.Whitepaper: